

Meta, the social media giant owned by Mark Zuckerberg, has been making significant strides in the AI space. Recently, they introduced their own “open-source Large Language Model” called LlaMa 2 to compete with tech giants like OpenAI, Google, and Microsoft. Now, they have taken things up a notch by unveiling their latest creation, AudioCraft, a text-to-voice-based generative AI model.
AudioCraft is designed to help users generate high-quality music and audio using simple text-based prompts. What sets it apart is that it trains on RAW audio signals, providing an authentic and realistic experience similar to Google’s audio AI tool, MusicLM.
The model behind AudioCraft consists of three distinct AI models: MusicGen, AudioGen, and EnCodec. MusicGen generates “music from text-based inputs,” using Meta’s owned and licensed music samples. AudioGen, on the other hand, creates “audio from text-based inputs,” by utilizing publicly available sound effects. Finally, the EnCodec decoder is responsible for producing true-to-life audio outputs with “minimal artifacts,” ensuring a seamless and synchronized final output.
With AudioCraft, you have the incredible ability to create various scenes effortlessly, incorporating individual elements that seamlessly synchronize in the final output. For instance, if you give the prompt “Rock music from the 90s with a bird chirping or river flowing in the background,” AudioCraft will use its MusicGen feature to produce the Rock music and its AudioGen feature to add the sound of a chirping bird and flowing river, blending them together flawlessly. The advanced decoding capabilities of EnCodec will then present this harmonious combination to you in the most realistic and immersive way possible.
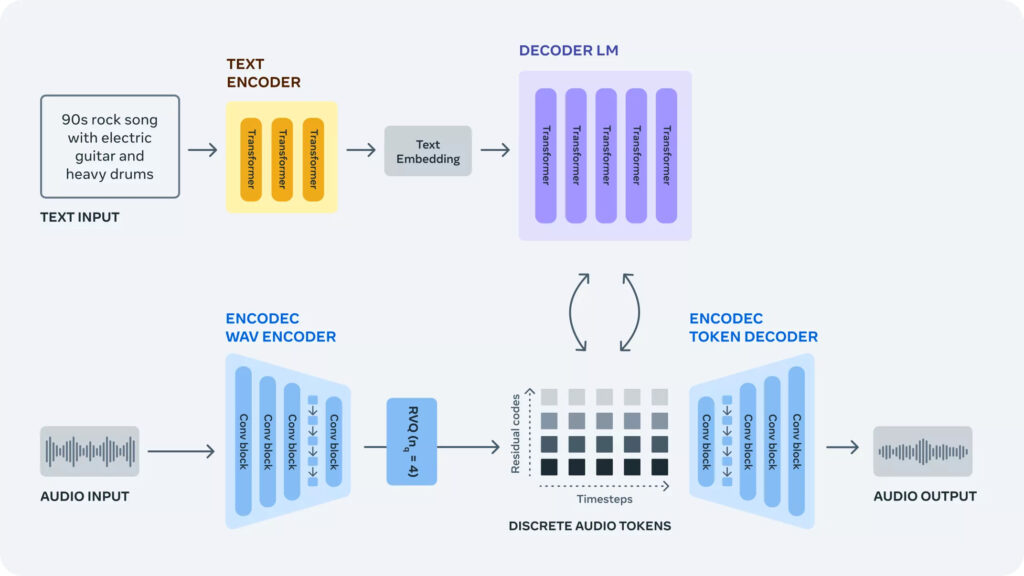
The real advantage of AudioCraft is not just its generative AI capabilities, but the fact that it is open-source. This means that researchers can access the source code of AudioCraft to gain a deeper understanding of the technology and create their own datasets to further improve it. The source code is available on GitHub, allowing users to build upon the existing code base and develop better sound generators and compression algorithms.
With AudioCraft, users can easily generate music, sound, and create compression and generation algorithms. This versatility allows for continuous improvement and refinement, saving users from starting from scratch and building on the foundation of the existing dataset.
To experience AudioCraft’s text-to-music generation capabilities, users can try MusicGen through Hugging Face. The possibilities for creativity and innovation with this AI model are exciting, and users are encouraged to share their experiences and feedback.



