
The term ‘natively multimodal’ has been circulating in the AI space for over a year, but companies have been slow to unlock the full potential of multimodal AI until now. Google has finally introduced its latest “Gemini 2.0 Flash Experimental” model, which brings native image generation and editing capabilities.
You might be wondering, what’s so special about image generation? After all, AI image generation has been available in major AI chatbots like ChatGPT for a while now. However, when we generate images on ChatGPT or Gemini, the request is typically routed to a specialized diffusion-based model like DALL·E 3 or Imagen 3. These models are trained specifically on images and designed solely for image generation, acting as extensions to the main AI model rather than being an integral part of it.
However, language-vision models like Gemini are natively multimodal, meaning they can seamlessly understand, generate, and modify both text and images. Despite this capability, no tech company had made it accessible to users—until now. OpenAI showcased its native image generation feature with GPT-4o in 2024, but it was never officially released.
Native image generation offers greater consistency since multimodal models are trained on vast datasets spanning multiple modalities. This allows them to develop a deeper understanding of concepts and demonstrate broader world knowledge.
Beyond image generation, you can effortlessly edit images using simple prompts. For example, you can upload an image and ask the model to add hat, insert legible text, remove objects, and more. Unlike diffusion models, which regenerate the entire image with each modification, natively multimodal models preserve consistency across multiple edits.
Native Image Generation in Gemini 2.0 Flash Experimental
Currently, the native image generation feature is not available to the general public. The Gemini 2.0 Flash Experimental model, which includes this capability, is exclusively accessible on Google’s AI Studio (visit) for free.
After its preview phase on AI Studio, the model will eventually roll out to Gemini for wider use. In the meantime, I had the chance to test Gemini’s native image generation, and it was an exciting experience.
To start, I experimented with a visual guide to assess the model’s consistency. I asked Gemini to create a step-by-step visual guide on how to make an omelet, generating an image for each stage of the process.
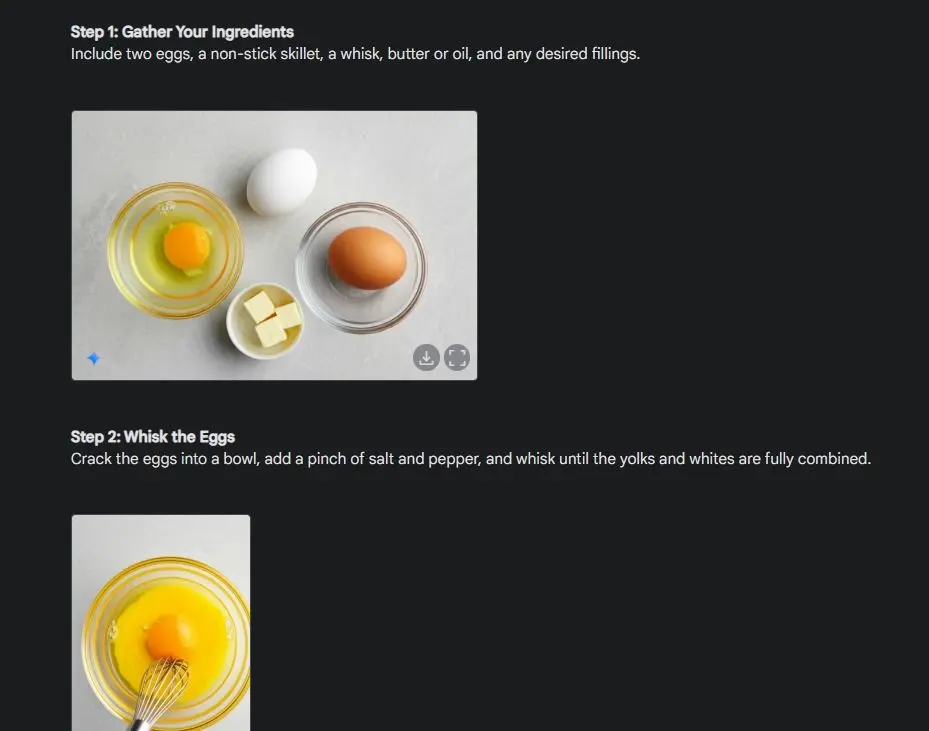



As you can see, the results are highly consistent across images, with no glitches. Even small details, like the bowl in the second image, remain the same. Additionally, you can download the images in 1024 x 680 resolution, allowing you to create visual guides on any topic with ease.
Next, I asked Gemini to generate an aesthetic table and then instructed it to show the table from a center camera angle. The result was flawless. I then prompted Gemini to add a PlayStation to the table and provide a closer look. Once again, Gemini delivered perfectly. Impressively, the AI even captured the reflection of the PS5 in the mirror behind it, demonstrating its advanced spatial awareness.

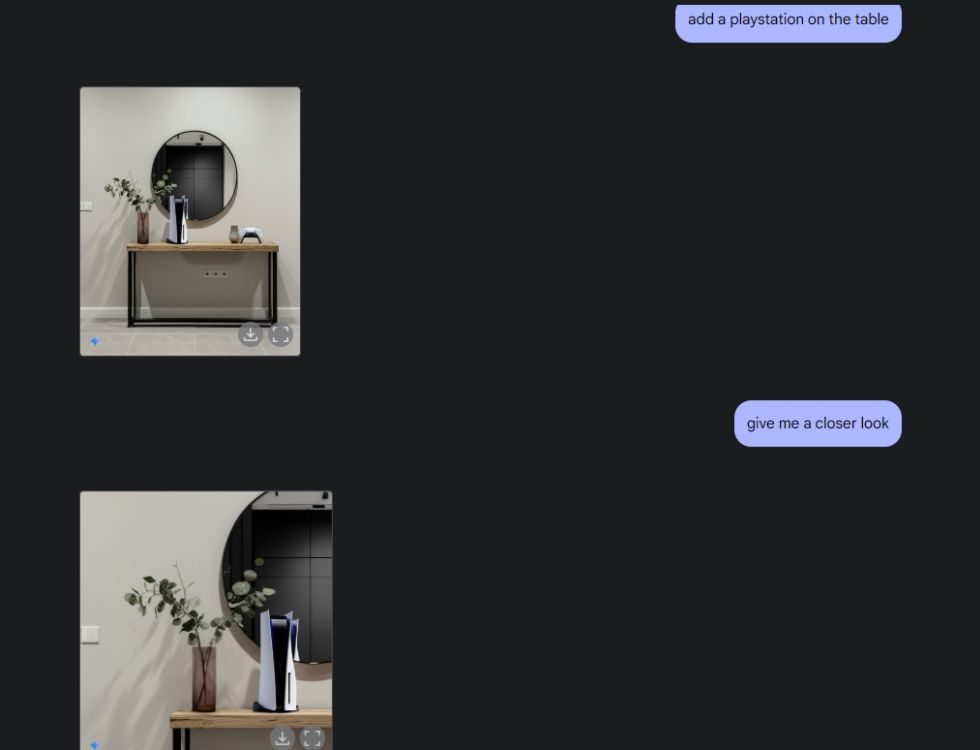
Native Image Generation in Gemini 2.0 Flash Experimental
To showcase native image editing, I uploaded an image from my gallery and asked Gemini 2.0 to remove the wine glass from the table. It executed the task flawlessly. Next, I instructed Gemini to add mushrooms to the pizza, and the result was seamless. Finally, I asked it to place a croissant on the table, and just like that, AI-powered image editing was in full effect thanks to Gemini’s native multimodal capability.


Lastly, I asked Gemini to colorize an image, and it did an impressive job. The final result looked even more vibrant and refined than the original, with no strange glitches, artifacts, or missing details.
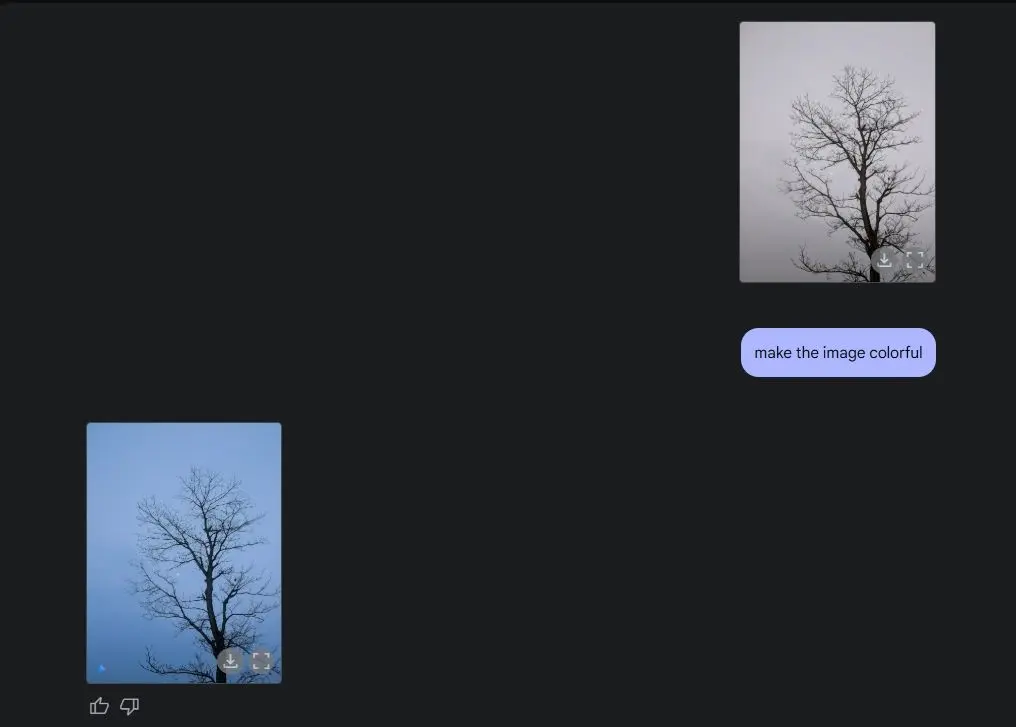
There are countless use cases to explore with Gemini’s new multimodal capabilities. Google has done an outstanding job with native image generation and editing, and I plan to test it more extensively in the coming weeks to push its limits.
With the release of Veo 2 for video generation and Imagen 3 for specialized image creation, Google seems to have outpaced OpenAI in several areas—not just AI text generation. It will be fascinating to see how OpenAI responds to reclaim the top spot with ChatGPT.


