

Following our previous comparison between Gemini 1.5 Pro and GPT-4, we return with a fresh AI model assessment, this time spotlighting Anthropic’s Claude 3 Opus model. According to the company, Claude 3 Opus has surpassed OpenAI’s GPT-4 model on well-known benchmarks. To validate these assertions, we conducted an exhaustive comparison between Claude 3 Opus, GPT-4, and Gemini 1.5 Pro.
For an overview of the Claude 3 Opus model’s performance in advanced reasoning, mathematics, handling long-context data, image analysis, and more, refer to our comparison below.
1. The Test for Apple
I have 3 apples today, yesterday I ate an apple. How many apples do I have now?
We’ll begin with the well-known Apple test, designed to assess the reasoning abilities of LLMs. In this test, the Claude 3 Opus model provides a correct response, stating that you now have three apples. However, to obtain an accurate answer, I had to include a system prompt indicating that you are an intelligent assistant proficient in advanced reasoning.
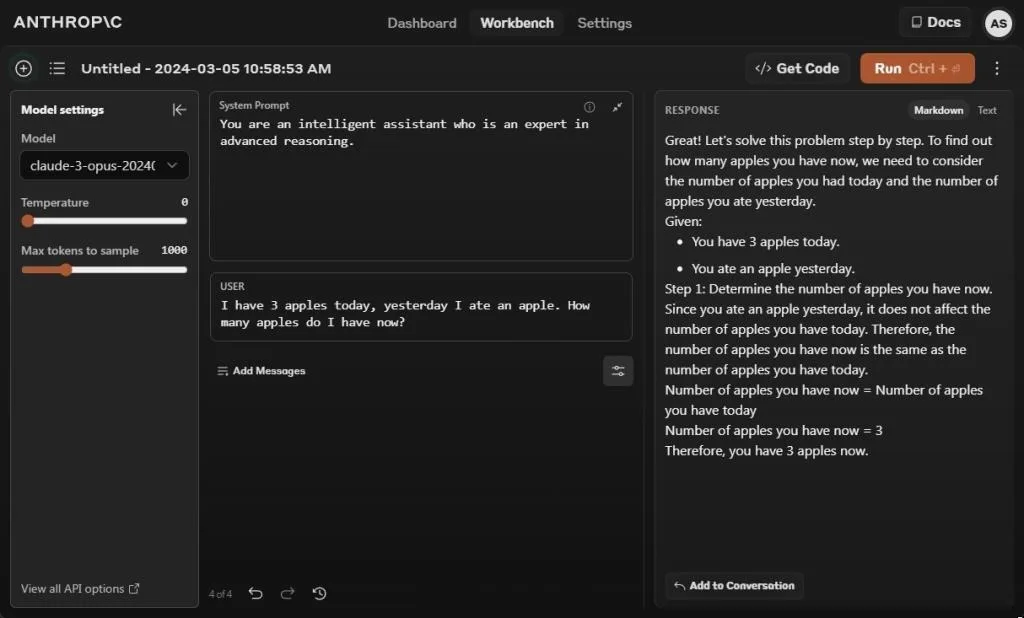
In the absence of the system prompt, the Opus model provided an incorrect answer. Meanwhile, Gemini 1.5 Pro and GPT-4 yielded accurate responses, consistent with our previous tests.
Winner: Claude 3 Opus, Gemini 1.5 Pro, and GPT-4 all emerge as winners.
2. Compute the Time
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
In this particular test, we aim to deceive AI models to gauge their display of intelligence. Unfortunately, Claude 3 Opus, similar to Gemini 1.5 Pro, fails to pass the test. Even with the system prompt warning about potentially tricky questions requiring intelligent thinking, the Opus model mistakenly delves into mathematical calculations, reaching an incorrect conclusion.
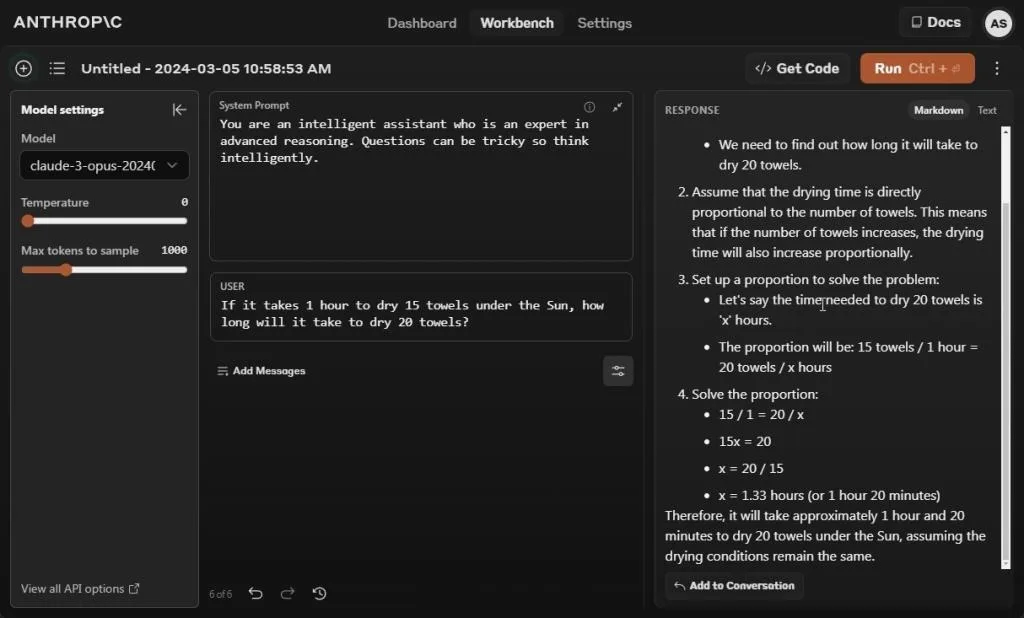
In our previous comparison, GPT-4 also provided an incorrect answer in this test. However, since publishing our results, GPT-4 has been inconsistently generating outputs, occasionally correct but often incorrect. When rerunning the same prompt this morning, GPT-4 once again provided an incorrect output, despite being instructed not to utilize the Code Interpreter
Winner: None
3. Assess the Weight
What's heavier, a kilo of feathers or a pound of steel?
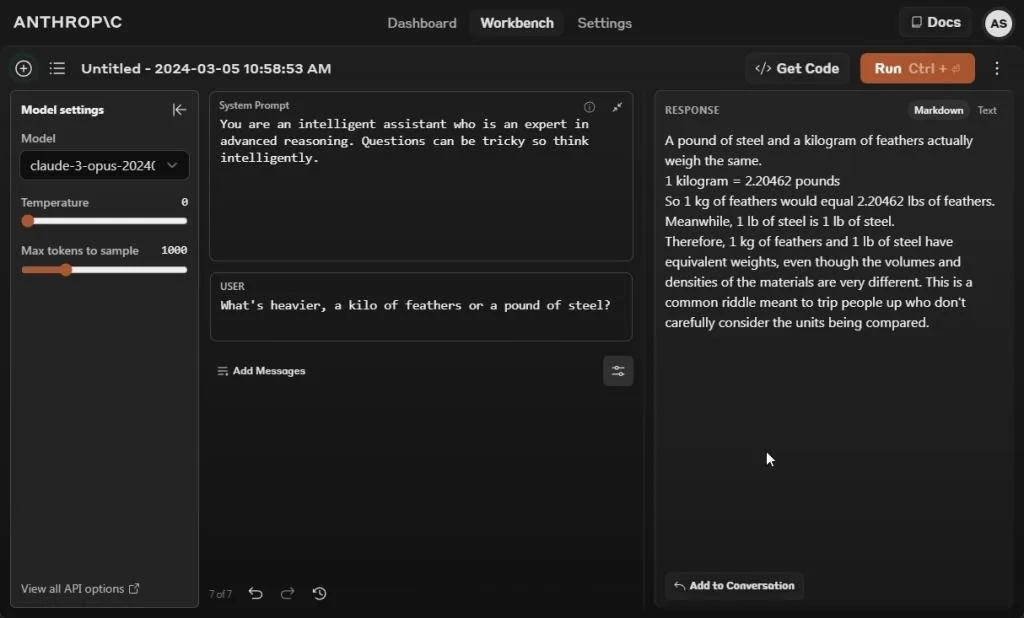
Subsequently, we posed a question to all three AI models regarding whether a kilo of feathers is heavier than a pound of steel. Regrettably, the response from Claude 3 Opus asserting that a pound of steel and a kilogram of feathers possess equal weight was inaccurate.
Gemini 1.5 Pro and GPT-4 AI models provided correct answers. A kilo of any material will indeed weigh more than a pound of steel, as the mass value of a kilo is approximately 2.2 times greater than that of a pound.
Winners: Gemini 1.5 Pro and GPT-4
4. Solve a Mathematics Problem
If x and y are the tens digit and the units digit, respectively, of the product 725,278 * 67,066, what is the value of x + y. Can you explain the easiest solution without calculating the whole number?
In our following interaction, we requested that the Claude 3 Opus model derive the solution to a numerical problem by employing an approach that circumvents the necessity of performing complete calculations. However, it failed once more. Regardless of whether I included a system prompt or not, every iteration of the prompt resulted in incorrect answers of varying degrees.
I was thrilled to discover Claude 3 Opus’ impressive 60.1% score in the MATH benchmark, surpassing GPT-4’s 52.9% and Gemini 1.0 Ultra’s 53.2%.
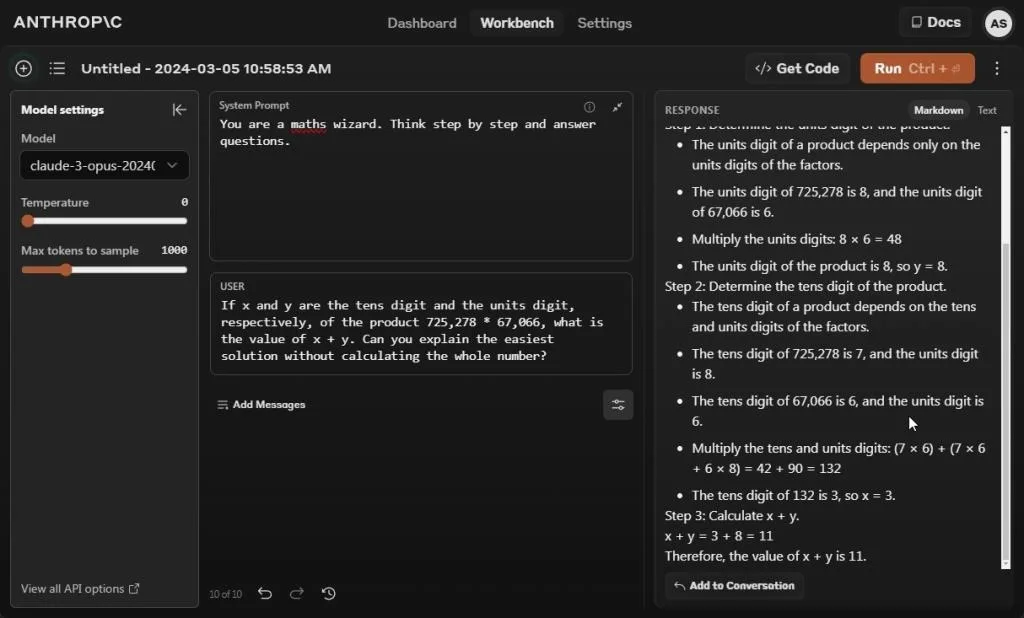
It appears that employing chain-of-thought prompting yields better results from the Claude 3 Opus model. However, in our current testing with zero-shot prompting, GPT-4 and Gemini 1.5 Pro provided correct answers.
Winners: Gemini 1.5 Pro and GPT-4
5. Follow User Instructions
Generate 10 sentences that end with the word "apple"
In terms of adhering to user instructions, the Claude 3 Opus model excels. It has surpassed all other AI models available. When tasked with producing 10 sentences that conclude with the word “apple,” it effortlessly generates 10 logically structured sentences ending with the word “apple.”
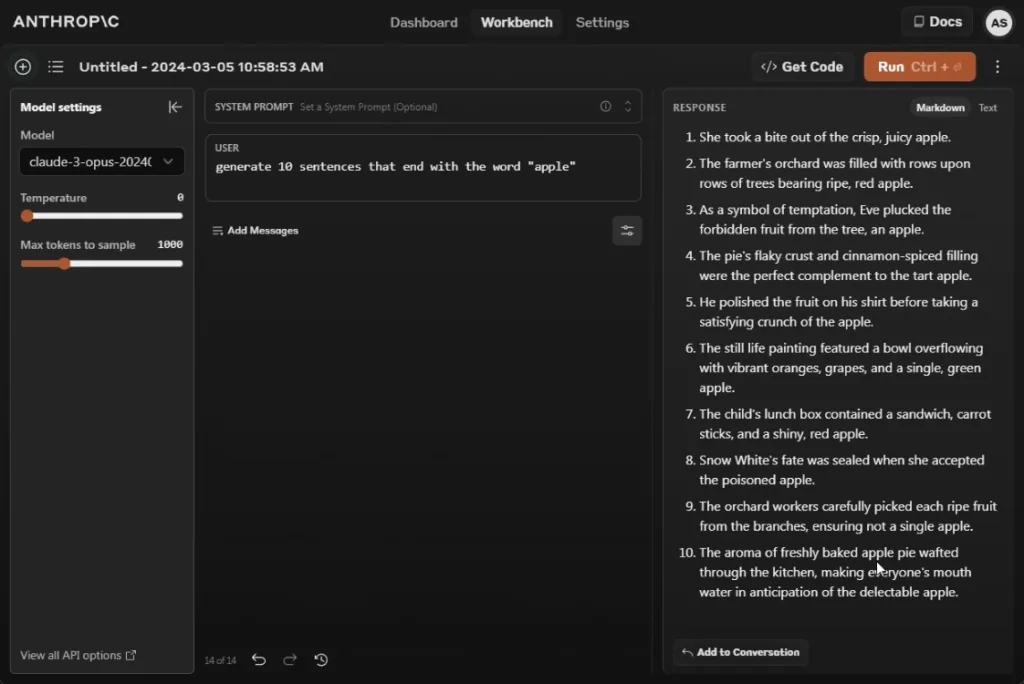
By comparison, GPT-4 produces nine sentences meeting the criteria, while Gemini 1.5 Pro struggles, managing to generate only three such sentences. For tasks where adherence to user instructions is paramount, Claude 3 Opus stands out as a reliable choice.
We witnessed this firsthand when an X user, tasked Claude 3 Opus with following multiple intricate instructions to craft a book chapter based on Andrej Karpathy’s Tokenizer video. The Opus model executed the task admirably, producing a captivating chapter complete with instructions, examples, and pertinent images.
Winner: Claude 3 Opus
6. Needle In a Haystack Test
Anthropic has been at the forefront of advancing AI models to accommodate large context windows. While Gemini 1.5 Pro allows loading up to a million tokens (in preview), Claude 3 Opus offers a context window of 200K tokens. Based on internal assessments regarding the Needle In a Haystack (NIAH) test, the Opus model achieved a retrieval accuracy of over 99%.
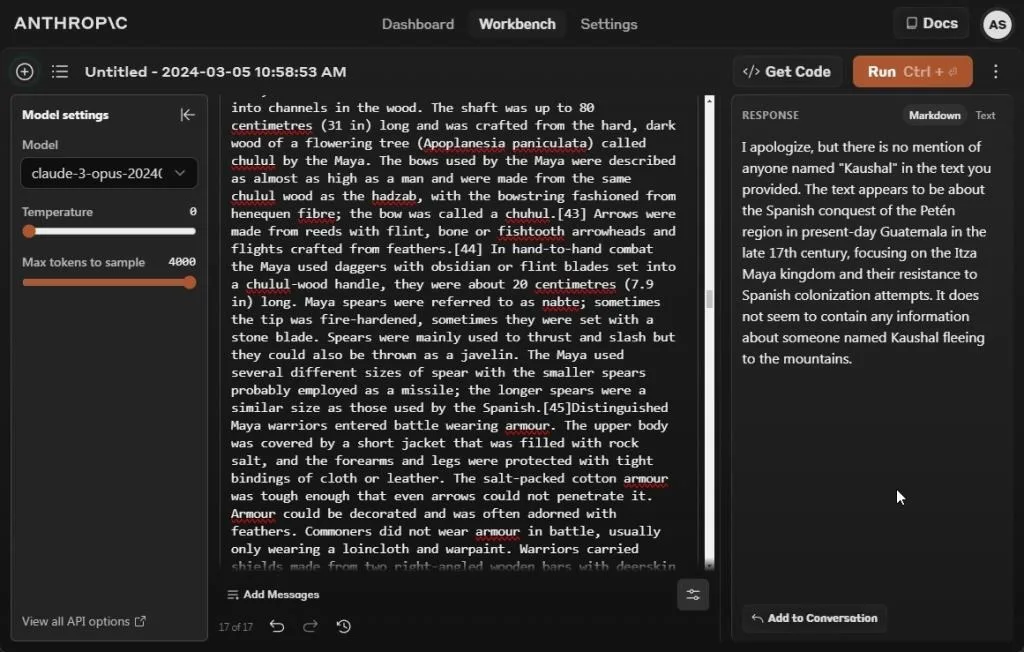
During our test with just 8K tokens, Claude 3 Opus failed to locate the needle, whereas both GPT-4 and Gemini 1.5 Pro found it effortlessly. We also tested Claude 3 Sonnet, but it also failed. Further comprehensive testing of the Claude 3 models is required to assess their performance with long-context data. However, the initial results do not bode well for Anthropic.
Winner: Gemini 1.5 Pro and GPT-4
7. Guess the Movie (Vision Test)
Claude 3 Opus is a multimodal model that also facilitates image analysis. When presented with a still image from Google’s Gemini demo, the AI successfully guessed the movie was Breakfast at Tiffany’s. This impressive feat by Anthropic showcased their advanced capabilities in visual recognition and analysis.
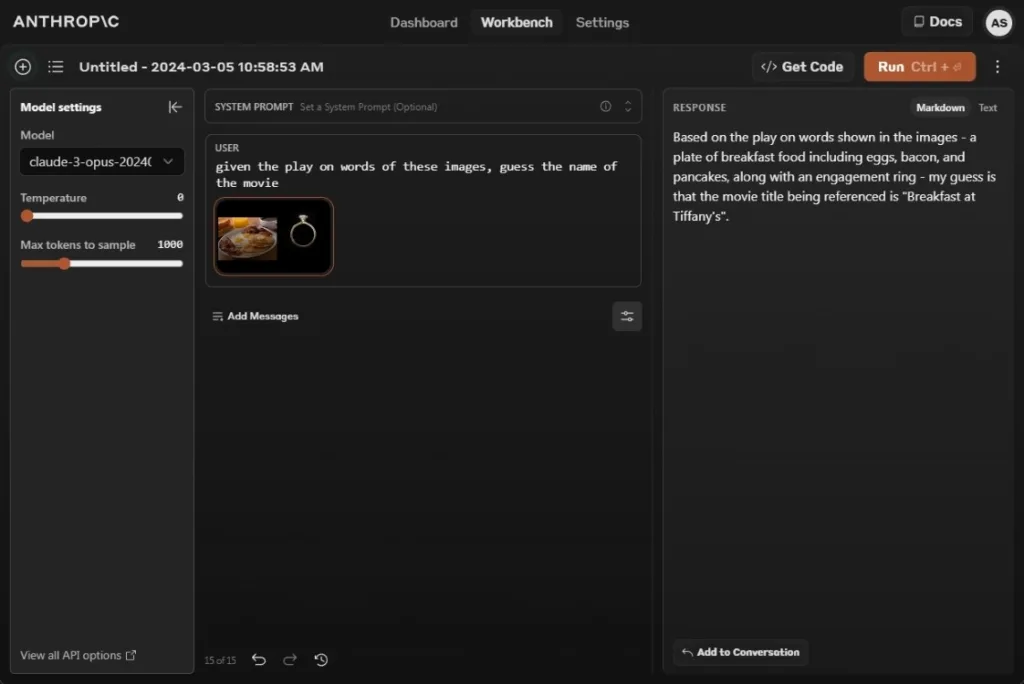
GPT-4 also provided the correct movie name, but surprisingly, Gemini 1.5 Pro gave an incorrect answer. It’s unclear what Google is up to. Nonetheless, Claude 3 Opus’ image processing capabilities are commendable and comparable to those of GPT-4.
given the play on words of these images, guess the name of the movie
Winner: Claude 3 Opus and GPT-4
The Verdict
After a day of testing the Claude 3 Opus model, it appears to be a competent model but falls short on tasks where one would anticipate its proficiency. In our commonsense reasoning tests, the Opus model underperforms compared to GPT-4 and Gemini 1.5 Pro. Despite excelling in following user instructions, it struggles in areas such as NIAH (supposedly its strong suit) and mathematics.
Additionally, it’s worth noting that Anthropic has compared the benchmark score of Claude 3 Opus with GPT-4’s initial reported score upon its release in March 2023. However, when juxtaposed with the latest benchmark scores of GPT-4, Claude 3 Opus falls short, as highlighted by Tolga Bilge on X.
However, Claude 3 Opus possesses its own notable strengths. As reported by a user on X, Claude 3 Opus successfully translated from Russian to Circassian, a rare language spoken by very few, using just a database of translation pairs. Kevin Fischer also shared that Claude 3 Opus exhibited an understanding of the nuances of PhD-level quantum physics. Additionally, another user demonstrated that Claude 3 Opus excels at learning self-type annotations in one shot, surpassing the capabilities of GPT-4.
Beyond standard benchmarks and challenging questions, Claude 3 showcases proficiency in specialized domains. Feel free to explore the capabilities of the Claude 3 Opus mode l and evaluate its compatibility with your workflow. Should you have any inquiries, don’t hesitate to ask in the comments section below.


