
Two weeks following the open-sourcing of Grok-1, xAI, spearheaded by Elon Musk, unveils the enhanced Grok-1.5 model. Promising enhanced reasoning abilities and an extended context length of 128,000 tokens, the AI startup announces that the model will initially be accessible to early testers and current Grok users on the X platform (previously known as Twitter) in the near future.
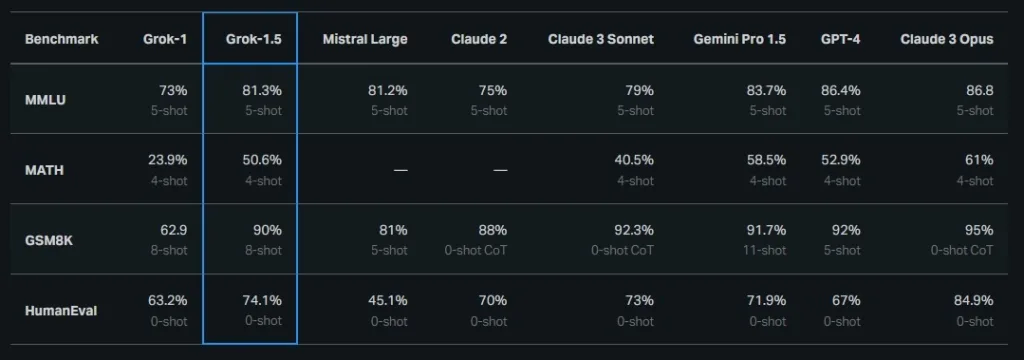
To demonstrate Grok-1.5’s problem-solving prowess, xAI conducted benchmark tests on well-known assessments. In the MMLU test, Grok-1.5 achieved an 81.3% score (5-shot), surpassing Mistral Large and Claude 3 Sonnet. In the MATH test, it attained a 50.6% score (4-shot), once again outperforming Claude 3 Sonnet. Notably, in the GSM8K test, it achieved an impressive 90% score, albeit with 8-shot prompting. Lastly, in the HumanEval test, Grok-1.5 scored 74.1% with 0-shot prompting.
xAI has expanded the context length of the Grok-1.5 model from 8K tokens to 128K tokens. To assess its retrieval capacity, the company conducted the NIAH test (Needle in a Haystack), achieving flawless results.
Although the parameter size of this incremental model remains undisclosed by xAI, Grok-1 is trained on an impressive 314 billion parameters, making it one of the largest open-source models available. Utilizing the Mixture-of-Experts (MoE) architecture, xAI has generously provided the model weights and architecture under the Apache 2.0 license, a commendable move.
Anthropic recently introduced its Claude 3 model series, showing considerable potential. In numerous instances, the largest Opus model has already surpassed OpenAI’s GPT-4 model. Reports suggest that OpenAI is developing an intermediate GPT-4.5 Turbo model, with plans for the release of GPT-5 in the summer of 2024. Additionally, Google’s Gemini 1.5 Pro model has showcased remarkable multimodal capabilities across an extensive context window.
In the realm of formidable proprietary models, xAI’s Grok-1.5 holds a position somewhere in between, judging by its benchmark performance. Its true prowess will be revealed through rigorous evaluation on reasoning tests. What are your thoughts on the Grok-1.5 model? Drop your opinions in the comments box underneath.



