

The speed of responses in ChatGPT, particularly with the GPT-4 model, may have been noticed as slower than desired. This issue is further exacerbated in voice assistant applications utilizing large language models such as ChatGPT’s Voice Chat feature or Gemini AI, which has replaced Google Assistant on Android phones, due to high latency LLMs. However, there is hope for improvement on the horizon thanks to Groq’s new powerful LPU (Language Processing Unit) inference engine.
Groq has made waves with its impressive technology. It’s worth noting that this is not to be confused with Elon Musk’s Grok, an AI model available on X (formerly Twitter). Groq’s LPU inference engine boasts an impressive capability to generate up to 500 tokens per second when running a 7B model, and around 250 tokens per second with a 70B model. This stands in stark contrast to OpenAI’s ChatGPT, which relies on GPU-powered Nvidia chips offering only around 30 to 60 tokens per second.
Groq is developed by Ex-Google TPU engineers.
Groq is not a chatbot but rather an AI inference chip, positioning itself as a competitor to industry giants like Nvidia in the AI hardware sector. It was established in 2016 by Jonathan Ross, who previously co-founded Google’s TPU (Tensor Processing Unit) team while working at Google. This team was responsible for developing Google’s initial TPU chip tailored for machine learning applications.
Following Ross’s departure from Google, several former members of the TPU team joined him at Groq, where they focused on designing hardware for the next generation of computing.
What is Groq’s LPU?
Groq’s LPU engine achieves remarkable speed compared to established players like Nvidia because it adopts a fundamentally different approach.
Groq’s CEO, Jonathan Ross, states that the company initially developed the software stack and compiler before designing the silicon. This approach prioritized a software-first mindset to ensure “deterministic” performance, a critical factor in achieving fast, accurate, and predictable results in AI inference.
Groq’s LPU architecture operates similarly to an ASIC chip (Application-specific integrated circuit) and is built on a 14nm node. Unlike general-purpose chips such as CPUs and GPUs, the LPU is custom-designed for a specific task, handling sequences of data in large language models. While CPUs and GPUs offer versatility, they may experience delayed performance and increased latency due to their broader functionality.
Groq employs a tailored compiler that precisely understands the chip’s instruction cycle, resulting in a significant reduction in latency. This compiler effectively allocates instructions to their appropriate locations, further diminishing latency. Moreover, every Groq LPU chip is furnished with 230MB of on-die SRAM, facilitating enhanced efficiency through high performance and low latency.
Addressing the question of whether Groq chips are suitable for training AI models, as previously mentioned, they are specifically designed for AI inferencing tasks. These chips lack high-bandwidth memory (HBM), which is essential for training and fine-tuning models. Therefore, Groq chips are not optimized for training AI models.
Groq asserts that the use of HBM memory introduces non-deterministic behavior to the overall system, resulting in increased latency. Therefore, Groq LPUs are not suitable for training AI models.
We Tested Groq’s LPU Inference Engine
Feel free to visit Groq’s website to witness their exceptional performance firsthand, without the necessity of creating an account or subscribing. Currently, they offer access to two AI models: Llama 70B and Mixtral-8x7B. To assess Groq’s LPU performance, we conducted tests using the Mixtral-8x7B-32K model, known as one of the top open-source models available.
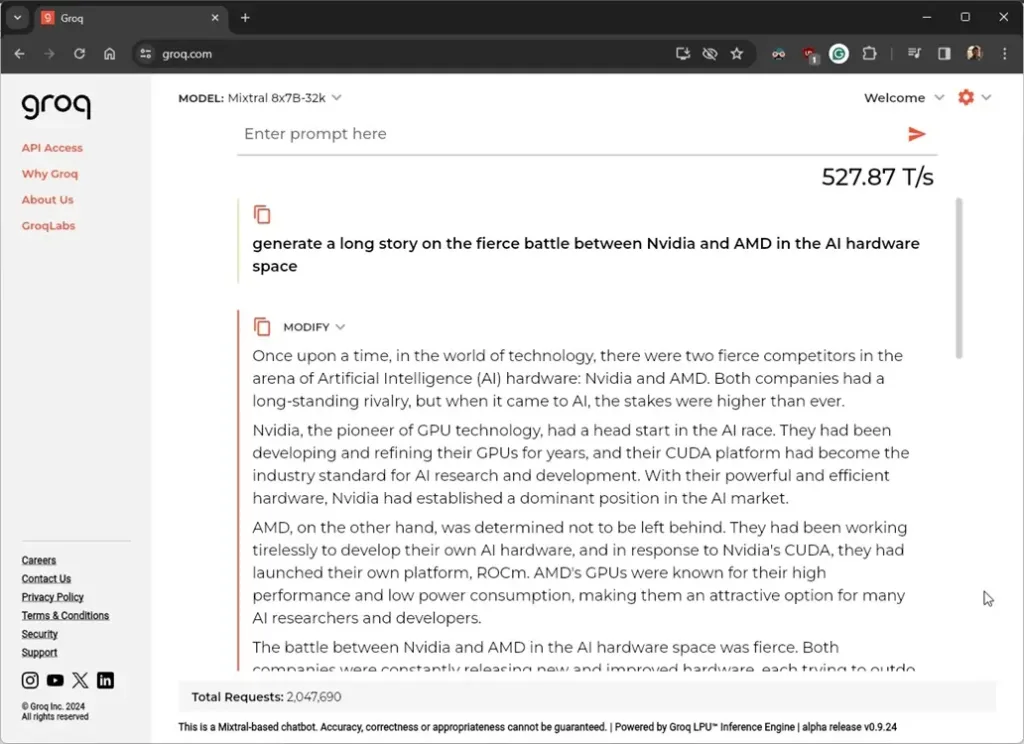
Groq’s LPU demonstrated impressive performance, generating output at a speed of 527 tokens per second. On a 7B model, it only took 1.57 seconds to generate 868 tokens (equivalent to 3846 characters). Even on a 70B model, its speed remained high at 275 tokens per second, significantly surpassing the competition.
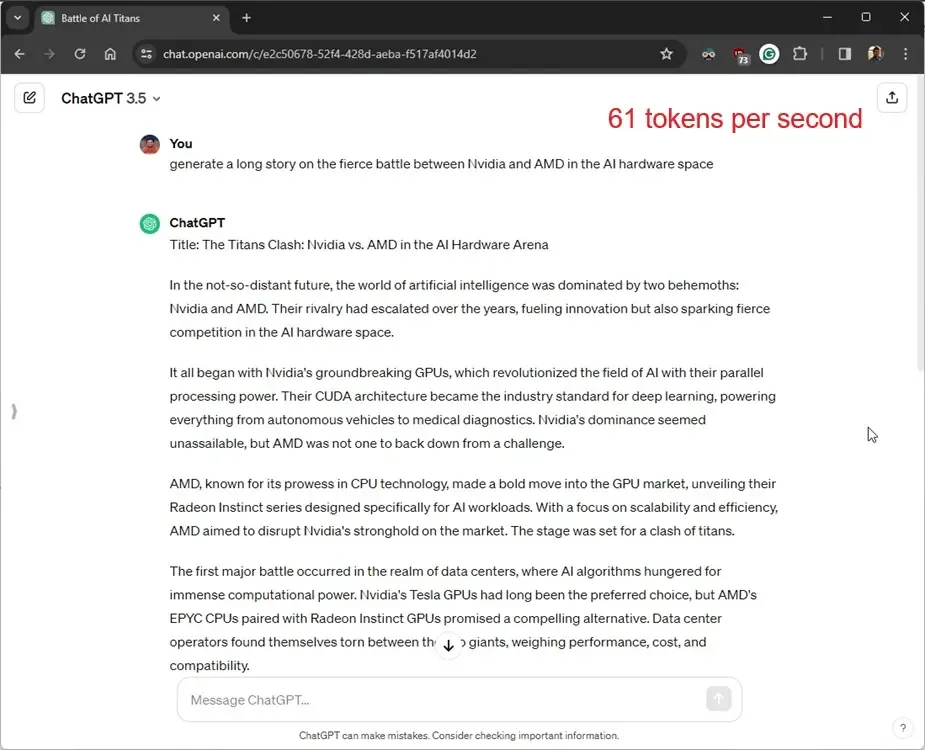
To assess Groq’s AI accelerator performance, we carried out a comparable test on ChatGPT (GPT-3.5, a 175B model), manually calculating the performance metrics.. ChatGPT, utilizing Nvidia’s Tensor-core GPUs, generated output at a rate of 61 tokens per second.It took around 9 seconds to generate 557 tokens, equivalent to 3090 characters.
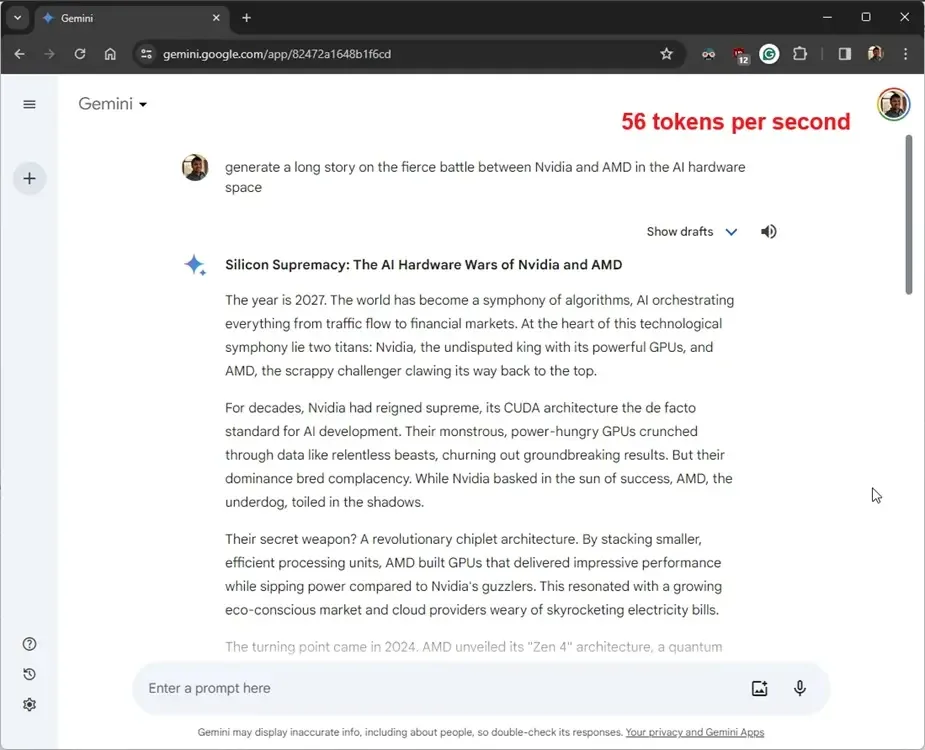
To facilitate a more comprehensive comparison, we conducted a similar test on the free version of Gemini (powered by Gemini Pro), which operates on Google’s Cloud TPU v5e accelerator. The exact model size of the Gemini Pro model has not been disclosed. It achieved a speed of 56 tokens per second, taking 15 seconds to generate 845 tokens (4428 characters).
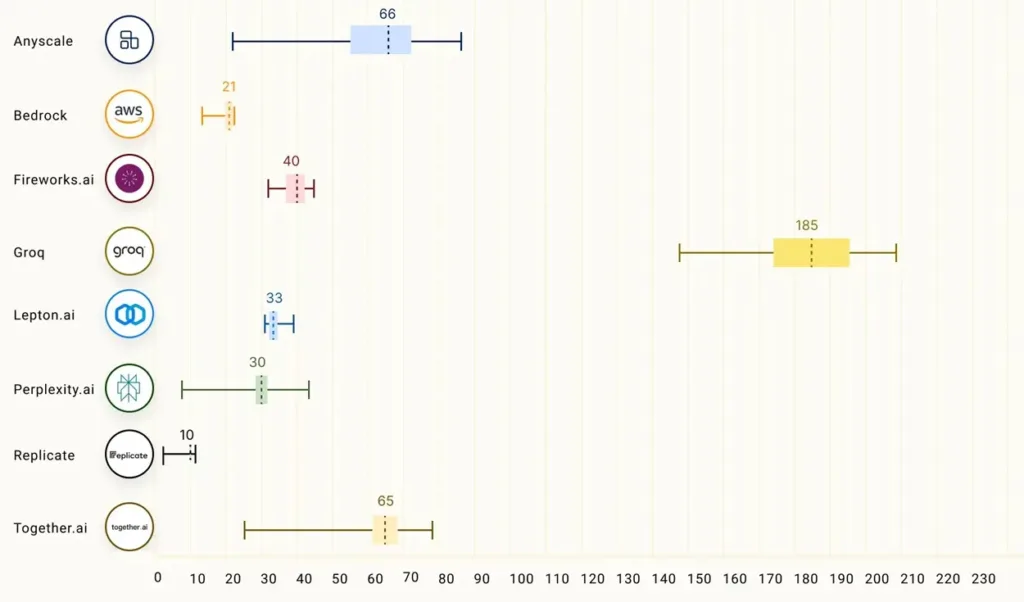
In contrast to other service providers, the ray-project conducted an extensive LLMPerf test and concluded that Groq outperformed other providers significantly.
Although not tested directly, it’s worth noting that Groq LPUs are not limited to language models alone; they also support diffusion models. According to the demo, they can generate various styles of images at a resolution of 1024px in under a second. This capability is indeed remarkable.
Groq vs Nvidia: What Does Groq Say?
According to a report by Groq, its LPUs are designed to be scalable and can be interconnected using optical interconnect technology across 264 chips. Further scalability is achievable using switches, although this may introduce additional latency. CEO Jonathan Ross has stated that the company is currently developing clusters capable of scaling across 4,128 chips, which are slated for release in 2025. These clusters will be built on Samsung’s 4nm process node.
In a benchmark test performed by Groq using 576 LPUs on a 70B Llama 2 model, the company achieved AI inference in just one-tenth of the time needed by a cluster of Nvidia H100 GPUs.
Additionally, while Nvidia GPUs consumed between 10 to 30 joules of energy to generate tokens in a response, Groq LPUs required only 1 to 3 joules.In summary, Groq asserts that its LPUs provide AI inference speeds that are 10 times faster than Nvidia GPUs, at only one-tenth of the cost.
What Does It Mean For End Users?
Overall, the development of LPUs is an exciting advancement in the AI space. With LPUs, users can experience instant interactions with AI systems, thanks to the significant reduction in inference time. This means users can interact with multimodal systems instantly, whether using voice, feeding images, or generating images.
Groq is already offering API access to developers, which suggests that we can expect much better performance of AI models in the near future. What are your thoughts on the development of LPUs in the AI hardware space? Share your thoughts in the comments below.


