
Once again, another AI model has outperformed GPT-4, at least according to benchmarks. This time, it’s Anthropic, the company founded by siblings Daniela and Dario Amodei, former members of OpenAI. The company has unveiled a new lineup of models known as Claude 3, featuring the Opus (largest and most capable), Sonnet (mid-size), and Haiku (smallest) models. According to Anthropic, the Claude 3 Opus model outperforms GPT-4 and Gemini 1.0 Ultra on all popular benchmarks.
Claude 3 Benchmarks
Anthropic has conducted tests on all three models using popular benchmarks such as MMLU, GPQA, GSM8K, MATH, HumanEval, HellaSwag, and others. In the MMLU test, Claude 3 Opus scored 86.8%, surpassing GPT-4’s reported score of 86.4%. Gemini 1.0 Ultra achieved 83.7% using the same 5-shot prompting technique.
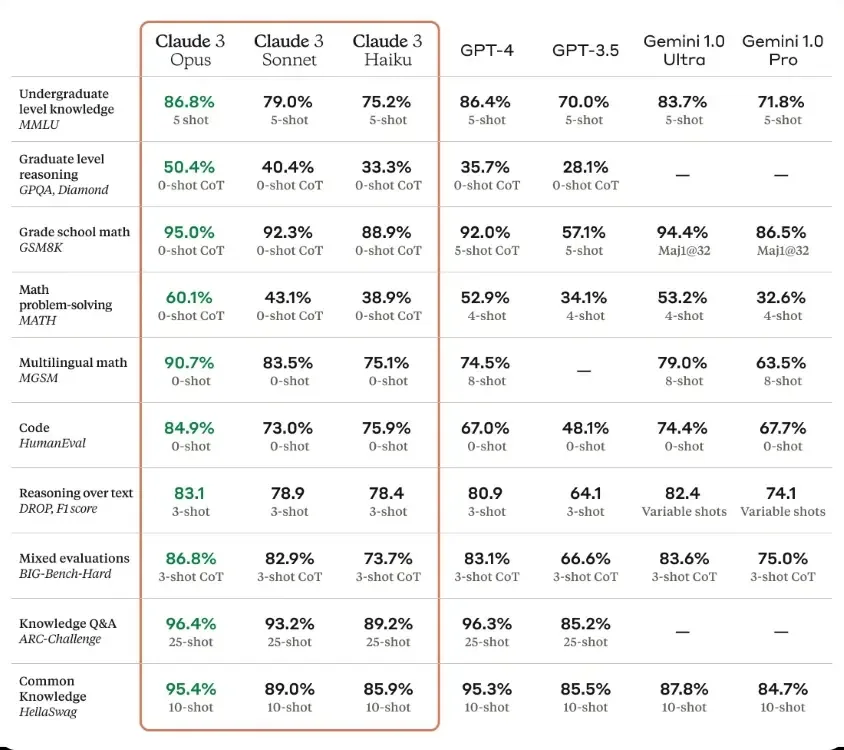
On the HumanEval benchmark, which assesses coding ability, the Opus model achieved a score of 84.9%, significantly higher than GPT-4’s 67% and Gemini 1.0 Ultra’s 74.4%. In the HellaSwag test, the Claude 3 Opus model also outperformed GPT-4 but with a slight margin, scoring 95.4% compared to GPT-4’s 95.3% and Gemini 1.0 Ultra’s 87.8%.
Claude 3 Capabilities
The largest Claude 3 Opus model shows great promise, and we will be testing it against GPT-4, Gemini 1.5 Pro, and Mistral Large, so stay tuned for updates. Anthropic also highlights that all three models excel in analysis and forecasting, nuanced content creation, code generation, and fluency in international languages such as Spanish, Japanese, and French.
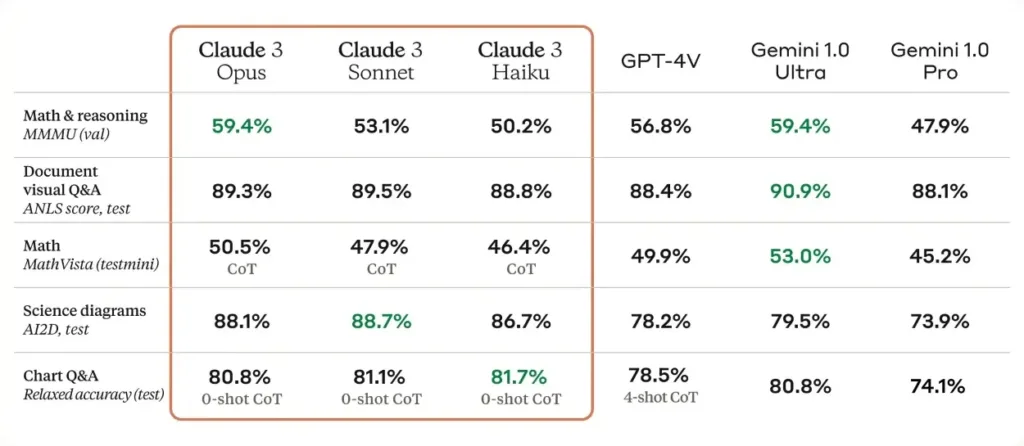
While the Claude 3 models do have vision capabilities, Anthropic is not marketing them as multimodal models. Instead, they emphasize that the vision capability can assist enterprise customers in processing charts, graphs, and technical diagrams. In benchmark tests, the vision capability performs better than GPT-4V but slightly lags behind Gemini 1.0 Ultra.
200K Context Length
Anthropic has announced that all three models in the Claude 3 family will initially offer a context window of 200,000 tokens, which is quite large. They also mention that these models can process more than 1 million tokens, but this capability will be available to select customers only.
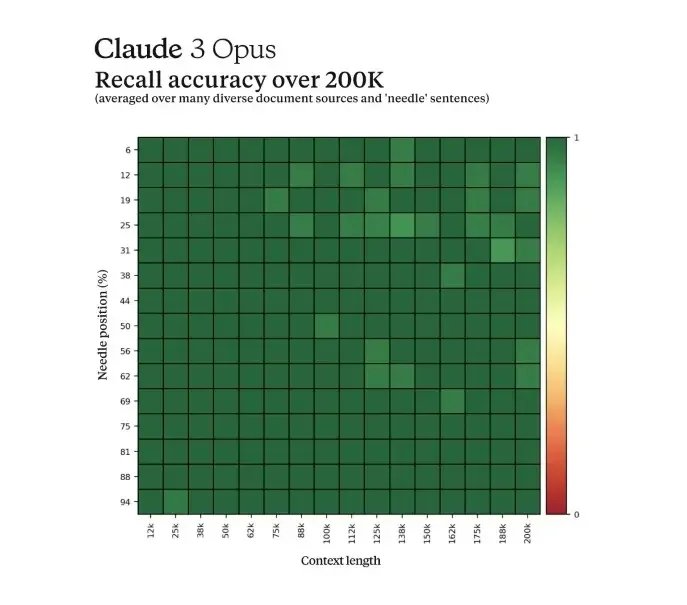
In the Needle In A Haystack (NIAH) test with over 200,000 tokens, the Opus model performed exceptionally well with over 99% accurate retrieval, similar to Gemini 1.5 Pro. Claude has been known for its ability to retrieve information from long contexts, and this performance has significantly improved with Claude 3.
Performance and Price
Anthropic claims that the Claude 3 models are quite fast, with the largest Opus model offering similar performance to Claude 2 and 2.1 but with improved intelligence. The mid-size Sonnet model is nearly twice as fast as Claude 2 and 2.1, additionally, Anthropic mentions that Claude 3 models are significantly less likely to refuse to answer, addressing an issue present in earlier models.
To access the flagship Opus model, users can subscribe to Claude Pro for $23.60 after taxes. The mid-size Claude 3 Sonnet model is available on the free version of claude.ai (visit). Additionally, developers can instantly access APIs for both the Opus and Sonnet models.
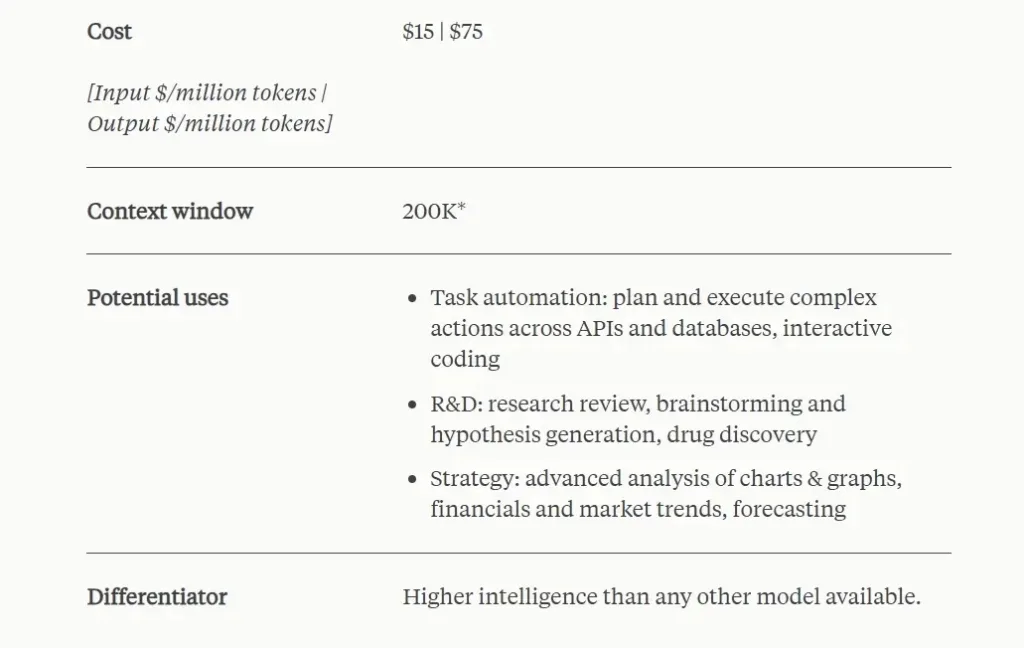
Regarding API pricing, the Claude 3 Opus model, with a 200,000-token context window, is priced at $15 per one million tokens for input and $75 per one million tokens for output. Compared to GPT-4 Turbo, which is priced at $10 for input and $30 for output with a 128,000-token context, the pricing appears to be relatively expensive.
However, what are your thoughts on the new family of models released by Anthropic, particularly the Opus model? Please let us know about your opinions in the comments section below.


