

In April 2024, Microsoft introduced its first AI model in the open-source Phi-3 family: Phi-3 Mini. Now, nearly a month later, the company has unveiled a new compact multimodal model called Phi-3 Vision. During Build 2024, Microsoft also presented two more Phi-3 family models: Phi-3 Small (7B) and Phi-3 Medium (14B). All these models are available under the open-source MIT license.
The Phi-3 Vision model is trained on 4.2 billion parameters, making it relatively lightweight. This is a significant milestone as it’s the first time a major corporation like Microsoft has open-sourced a multimodal model. It has a context length of 128K and can process images. Unlike Google’s PaliGemma model, which isn’t designed for conversational use, Phi-3 Vision is versatile.
Microsoft mentions that the Phi-3 Vision model was trained on publicly available, high-quality educational and code data, supplemented by synthetic data for math, reasoning, general knowledge, charts, tables, diagrams, and slides.
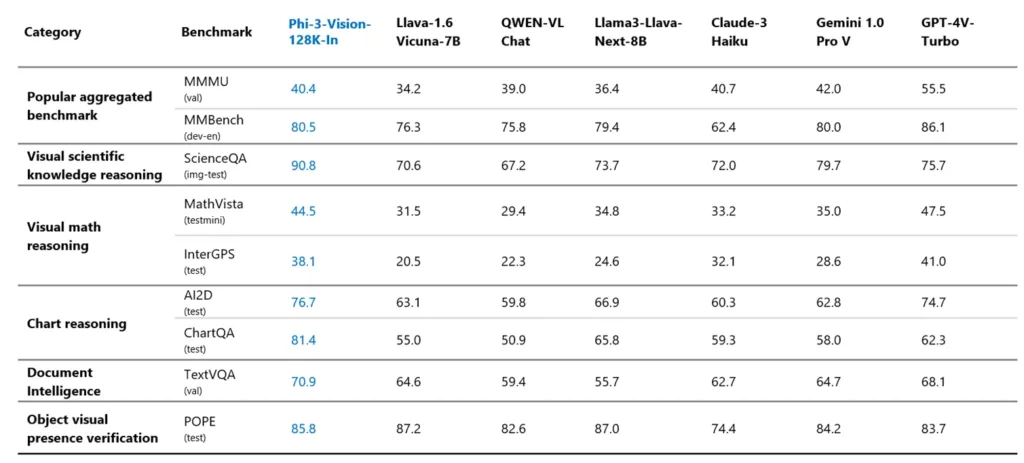
Despite its smaller size, the Phi-3 Vision model outperforms various models like Claude 3 Haiku, LlaVa, and Gemini 1.0 Pro on several multimodal benchmarks and comes near to OpenAI’s GPT-4V model. Microsoft indicates that developers can use the Phi-3 Vision model for general image understanding, OCR tasks, chart and table interpretation and much more.
If you want to check out the Phi-3 Vision model, visit Azure AI Studio (visit).



