
Although there are applications such as LM Studio and GPT4All for running AI models locally on computers, Android phones lack similar options. However, MLC LLM has introduced the MLC Chat Android app, allowing users to download and execute LLM models directly on their Android devices. This app supports small AI models ranging from 2B to 8B, including Llama 3, Gemma, Phi-2, Mistral, and others. Let’s get started with the process.
- Get the MLC Chat app (Free) for Android phones by downloading the APK file (148MB) and installing it.
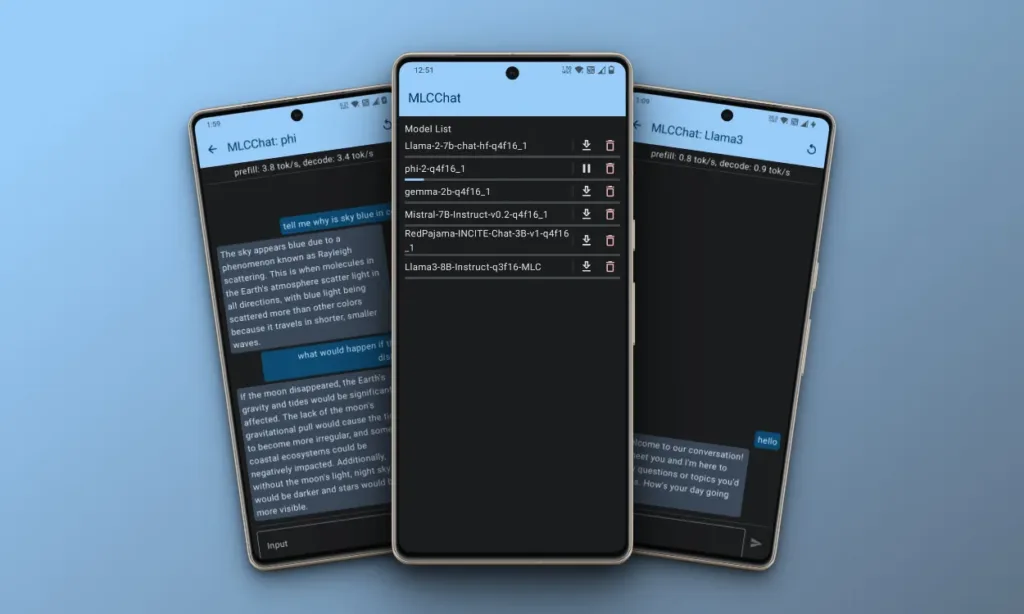
- Open the MLC Chat app, where you’ll find a list of AI models including the latest Llama 3 8B model, Phi-2, Gemma 2B, and Mistral 7B.
- Choose and download the AI model of your preference. For example, I opted for Microsoft’s Phi-2 model due to its compact size and efficient performance.
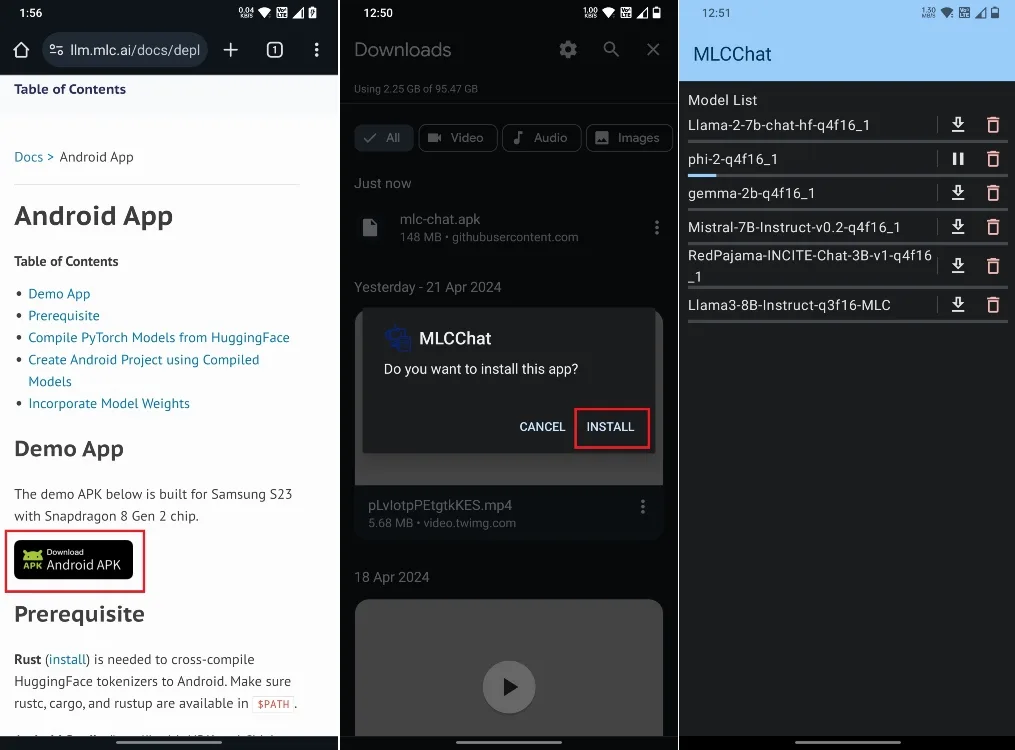
- After downloading the model, simply tap the chat button next to it.
- Now, start conversations with the AI model directly on your Android device without internet connectivity.
- During my testing, Phi-2 performed well on my phone, albeit with occasional hallucinations. However, Gemma didn’t run, and Llama 3 8B operated sluggishly.

- Phi-2 produced an output of 3 tokens per second on my OnePlus 7T, which uses the Snapdragon 855+ SoC, an older chip from five years ago.
Here’s how you can download and run LLM models directly on your Android device. While the token generation may be sluggish, this method demonstrates that running AI models locally on Android phones is now possible. Currently, it utilizes only the CPU; however, with the Qualcomm AI Stack integration, Android devices powered by Snapdragon can utilize the dedicated NPU, GPU, and CPU to deliver significantly improved performance.
Developers on the Apple side are currently leveraging the MLX framework for rapid local inferencing on iPhones, achieving a token generation rate of nearly 8 tokens per second. It’s expected that Android devices will also gain support for on-device NPUs, resulting in excellent performance. According to Qualcomm’s own statements, the Snapdragon 8 Gen 2 has the capability to produce 8.48 tokens per second when processing a larger 7B model, with improved performance expected when handling a 2B quantized model.
That wraps up our discussion. If you’re interested in interacting with your documents using a local AI model, be sure to check out our dedicated article. If you encounter any difficulties, feel free to share them in the comments below.



