

At the Google Cloud Next 2024 event in Las Vegas, Google announced the general availability of Gemini 1.5 Pro to all users. This long-awaited model is now in public preview, featuring a 1 million context window. Users no longer need to sign up for a waitlist to access the Gemini 1.5 Pro model.
I attempted to access the Gemini 1.5 Pro model from a new Google account and found it readily available without any wait. Best of all, this is all accessible for free.
However, this doesn’t mean you can immediately start using the Gemini 1.5 Pro model on the Gemini portal. To access the model currently, you’ll need to visit aistudio.google.com. After a few months of public preview, the model will be available on the Gemini portal. You’ll likely need a Gemini Advanced subscription to use the model.
It’s important to note that the Gemini 1.5 Pro model is a mid-tier model built on the MoE architecture. Despite this, it easily outperforms the largest Gemini 1.0 Ultra model. In our comparison with the GPT-4 model, Gemini 1.5 Pro demonstrated remarkable capabilities in several tests. When Gemini 1.5 Pro debuts on the Gemini portal, expect it to outperform both GPT-4 and Claude 3’s Opus model.
In addition, Gemini 1.5 Pro now offers audio file processing capabilities. Users can upload audio files of meetings or videos, and the model can automatically listen to them without the need to manually create a transcript. This feature can greatly benefit individuals looking to extract quick and structured information from audio meetings or discussions.
Gemini 1.5 Pro already had the ability to process videos and images, and now with added support for audio files, it has become a powerful multimodal model with a context length of 1 million tokens. We conducted tests on the audio processing capability of the Gemini 1.5 Pro model. Here are the results.
How to Process Audio Files on Gemini 1.5 Pro
1. Go to aistudio.google.com in your web browser.
2. Ensure that the “Gemini 1.5 Pro” model is selected from the drop-down menu.
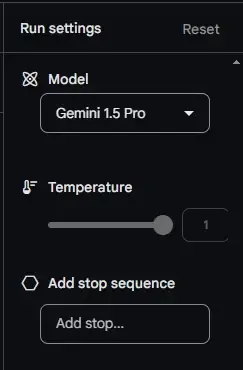
3. Click on the “Audio” menu at the top and upload your audio file. Supported formats include FLAC, MIDI, MP3, M4A, OPUS, OGG, OGA, WAV, and MID.
4. The model will process the audio file, using tokens.
5. Begin asking your questions, and Gemini 1.5 Pro will extract information from the audio and respond accordingly.
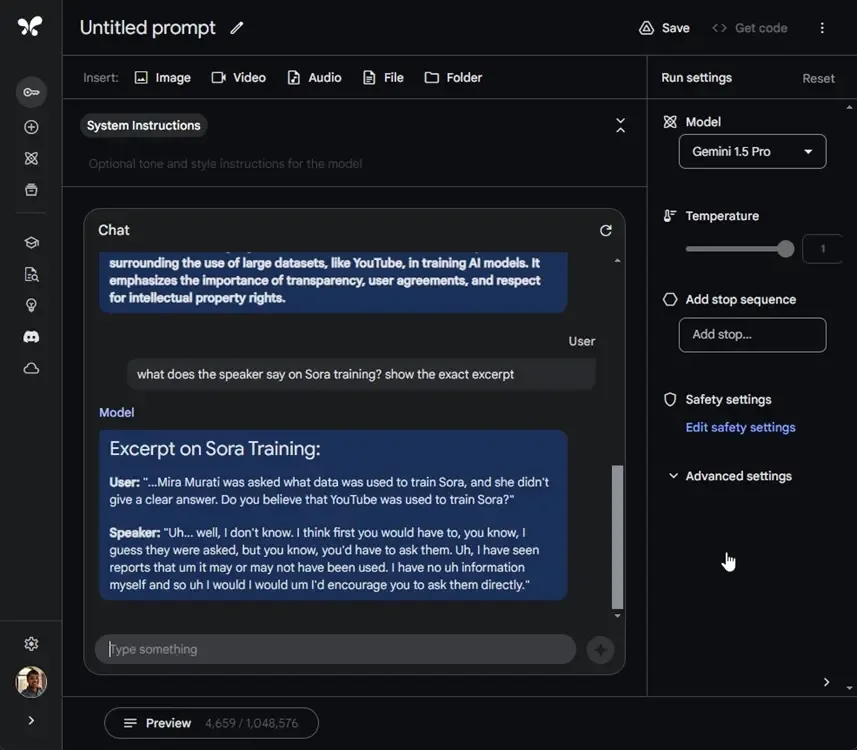
6. One of the key features is that it generates a structured transcript with labels for different speakers, and it does not generate irrelevant information.
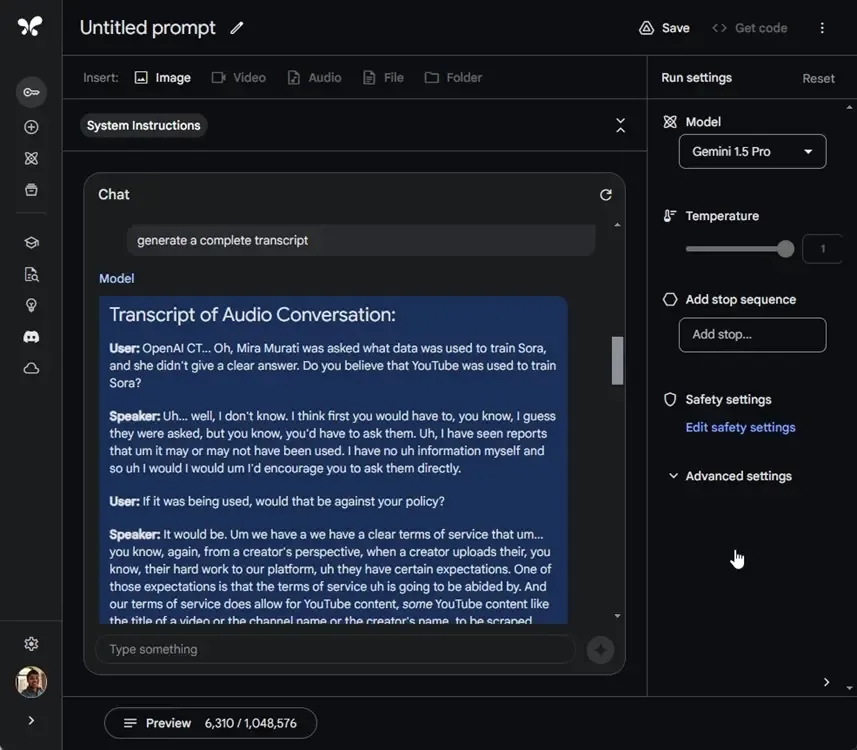
Here’s how you can upload and process audio files on Gemini 1.5 Pro. This model, developed by the Google DeepMind team, is exceptionally powerful, and I’m thrilled that it’s now accessible to everyone at no charge. Give it a try and share your thoughts with us in the comments section below.



