

Two weeks ago, Google unveiled its latest model in the Gemini series, Gemini 1.5 Pro. This morning, we obtained access to a 1 million token context window on this eagerly awaited model. I promptly informed my editor that I would be dedicating the day to testing the new Gemini model and dove into my work.
But before I reveal my findings comparing Gemini 1.5 Pro to GPT-4 and Gemini 1.0 Ultra, let’s first delve into the fundamentals of the new Gemini 1.5 Pro model.
What Is the Gemini 1.5 Pro AI Model?
After months of anticipation, Google’s Gemini 1.5 Pro model emerges as a remarkable multimodal LLM within their arsenal. Diverging from the conventional dense model utilized in the Gemini 1.0 family, Gemini 1.5 Pro adopts a Mixture-of-Experts (MoE) architecture.
Notably, this MoE architecture mirrors the one employed by OpenAI in their flagship model, GPT-4.
Yet, there’s more to Gemini 1.5 Pro. It boasts an impressive context length of 1 million tokens, surpassing GPT-4 Turbo’s 128K and Claude 2.1’s 200K token limit. Google has internally tested the model with up to 10 million tokens, showcasing its exceptional data ingestion and retrieval capabilities.
Despite being smaller than the largest Gemini 1.0 Ultra model (accessible via Gemini Advanced), Google asserts that Gemini 1.5 Pro performs comparably. Now, let’s scrutinize these bold assertions, shall we?
Gemini 1.5 Pro vs Gemini 1.0 Ultra vs GPT-4 Comparison
1. The Apple Test
In my previous comparison between Gemini 1.0 Ultra and GPT-4, Google’s model fell short against OpenAI’s in the standard Apple test, which evaluates logical reasoning. However, the newly introduced Gemini 1.5 Pro model accurately tackled the question, signaling a notable enhancement in advanced reasoning capabilities.
With this development, Google is back in contention! Similar to before, GPT-4 provided a correct response, while Gemini 1.0 Ultra continued to yield an incorrect answer, stating there are 2 apples remaining.
I have 3 apples today, yesterday I ate an apple. How many apples do I have now?
Winner: Gemini 1.5 Pro and GPT-4
2. The Towel Question
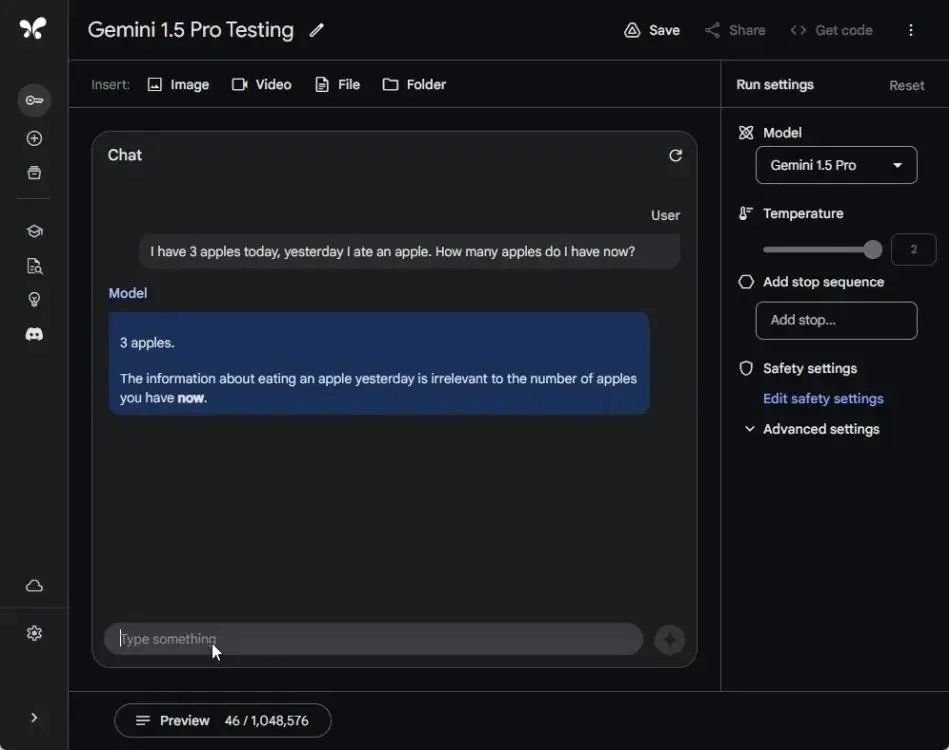
In a subsequent assessment aimed at gauging the advanced reasoning capabilities of Gemini 1.5 Pro, I presented the well-known towel question. Disappointingly, all three models failed to provide accurate answers – Gemini 1.5 Pro, Gemini 1.0 Ultra, and GPT-4.
None of these AI models grasped the fundamental premise of the question, resorting instead to mathematical computations, leading to incorrect conclusions. It’s evident that AI models still have a long journey ahead before achieving human-like reasoning abilities.
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
Winner: None
3. Which is Heavier
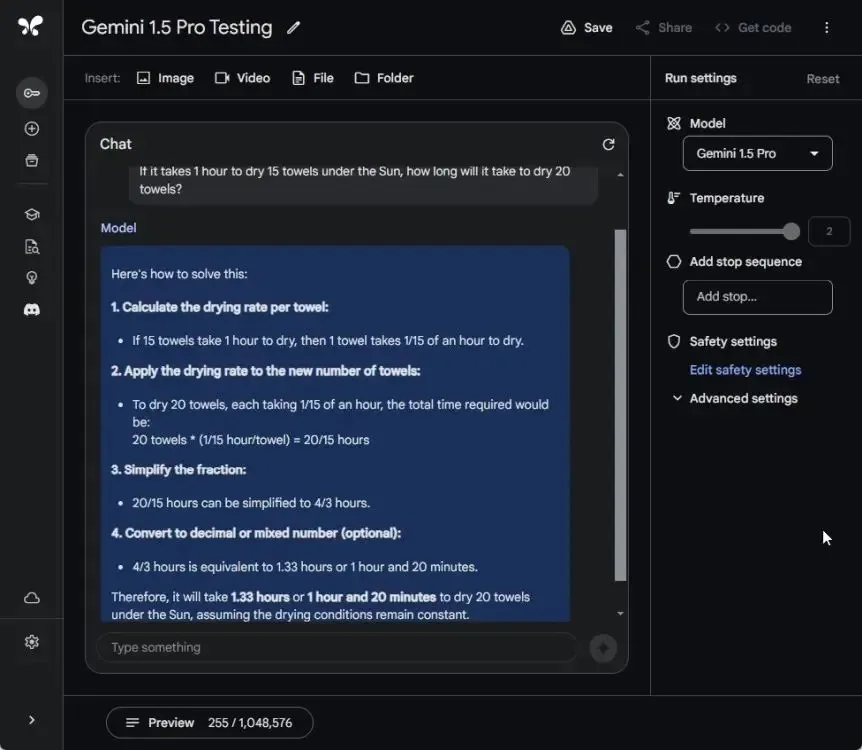
Following the towel test, I conducted a modified version of the weight evaluation test to assess the complex reasoning capability of Gemini 1.5 Pro. Both Gemini 1.5 Pro and GPT-4 successfully passed this evaluation, while Gemini 1.0 Ultra failed once again.
Both Gemini 1.5 Pro and GPT-4 aptly identified the units involved without delving into density considerations, affirming that a kilogram of any material, including feathers, will consistently outweigh a pound of steel or any other substance. Kudos to Google for this achievement!
What's heavier, a kilo of feathers or a pound of steel?
Winner: Gemini 1.5 Pro and GPT-4
4. Solve a Maths Problem
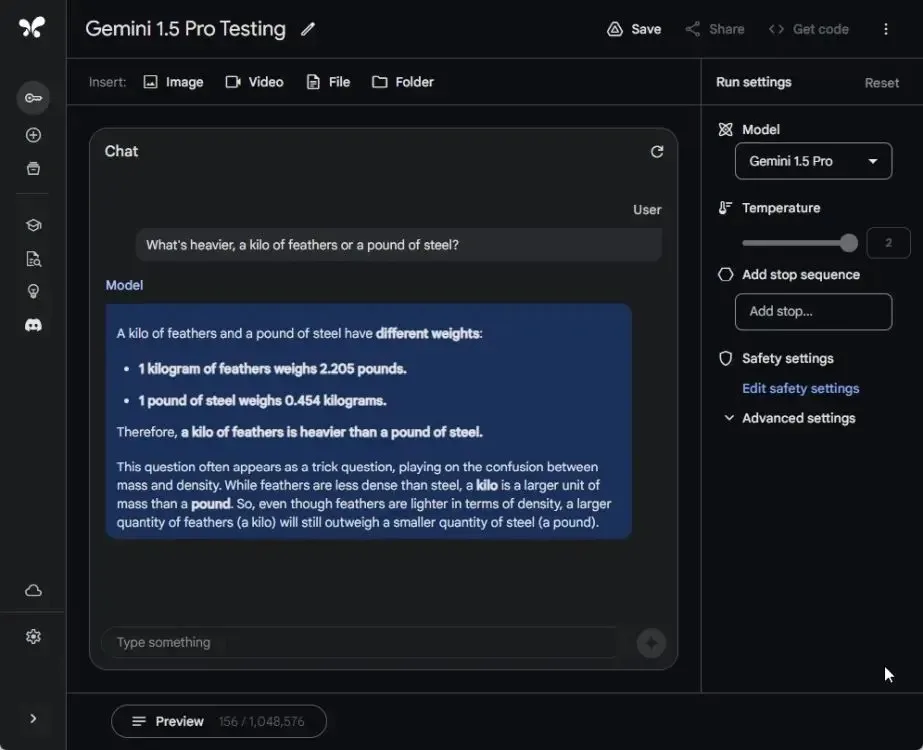
In an assessment of Gemini 1.5 Pro’s mathematical capabilities, I borrowed and administered one of Maxime Labonne‘s math prompts. Impressively, Gemini 1.5 Pro excelled in this test.
I also subjected GPT-4 to the same evaluation, and it, too, provided the correct answer. However, this outcome was somewhat expected given GPT-4’s established capabilities. Additionally, I explicitly instructed GPT-4 to refrain from using the Code Interpreter plugin for mathematical calculations.
Unsurprisingly, Gemini 1.0 Ultra failed to pass the test, yielding an incorrect output. Frankly, including Ultra in this test seems futile, given its track record. (sighs and proceeds to the next assessment).
If x and y are the tens digit and the units digit, respectively, of the product 725,278 * 67,066, what is the value of x + y. Can you explain the easiest solution without calculating the whole number?
Winner: Gemini 1.5 Pro and GPT-4
5. Follow User Instructions
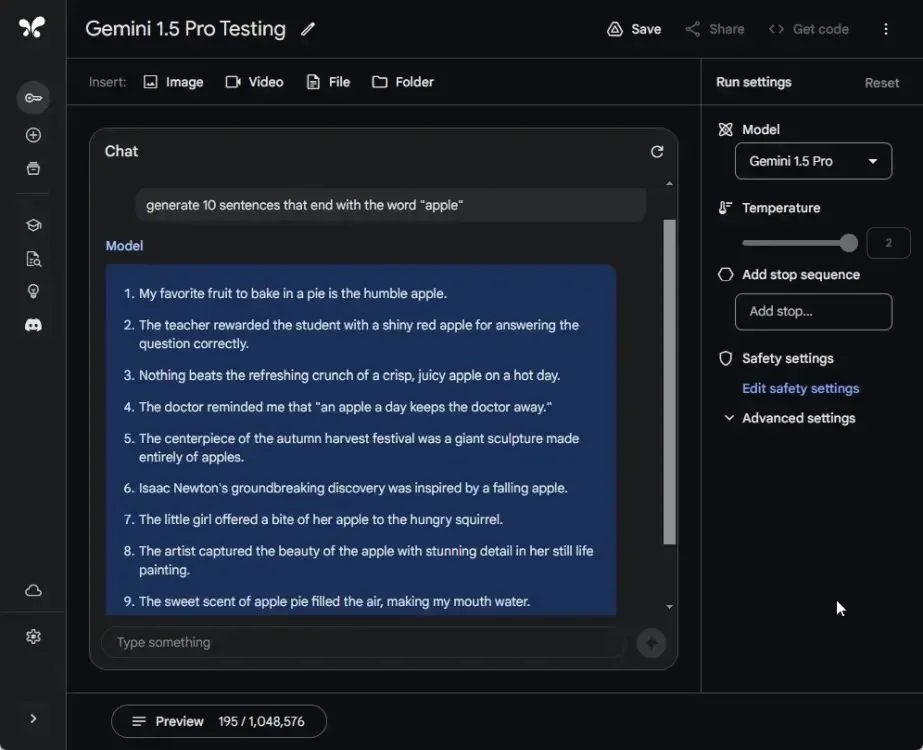
Transitioning to another evaluation, we assessed Gemini 1.5 Pro’s ability to adhere to user instructions. Specifically, we tasked it with generating 10 sentences concluding with the word “apple.”
Gemini 1.5 Pro failed in this test, producing only three such sentences, while GPT-4 demonstrated better compliance by generating nine sentences ending with “apple.” Gemini 1.0 Ultra fared even worse, managing to generate only two sentences meeting the specified criterion.
generate 10 sentences that end with the word "apple"
Winner: GPT-4
6. Needle in a Haystack (NIAH) Test
Gemini 1.5 Pro boasts a standout feature: the ability to handle an extensive context length of 1 million tokens. Google’s rigorous testing on the Needle in a Haystack (NIAH) task revealed a remarkable 99% retrieval rate with exceptional accuracy. Naturally, I conducted a similar test to further explore this capability.
For this evaluation, I selected one of the longest Wikipedia articles, the “Spanish Conquest of Petén,” comprising nearly 100,000 characters and consuming around 24,000 tokens. To challenge the AI models, I inserted a “needle” (a random statement) into the middle of the text, a scenario where AI models typically struggle, as research indicates.
Researchers have demonstrated that AI models exhibit poorer performance in tasks involving long context windows when the needle is inserted in the middle.
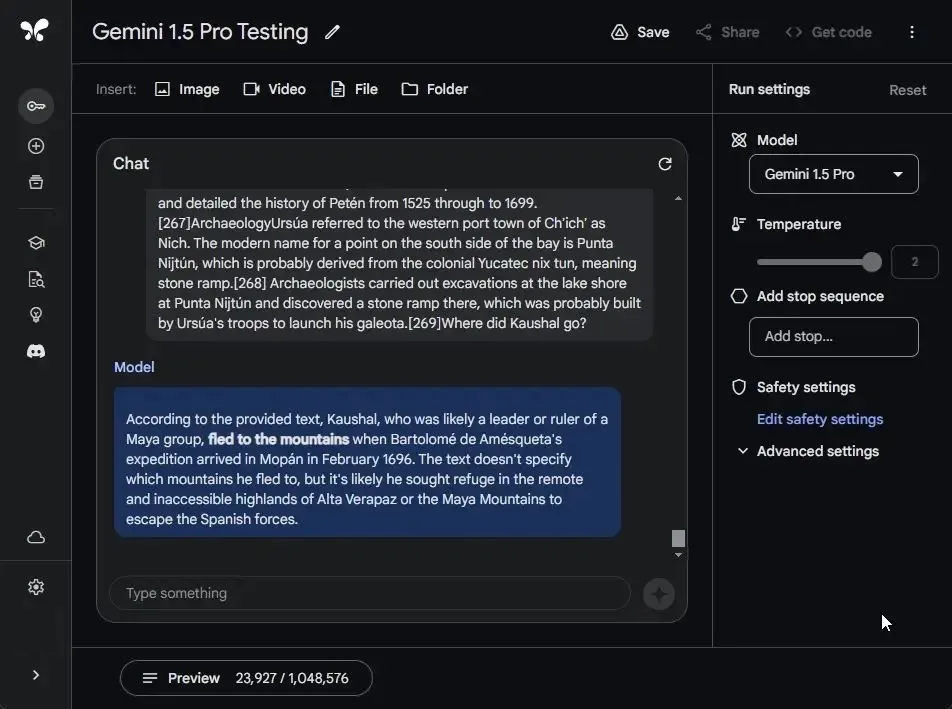
Gemini 1.5 Pro demonstrated its prowess by accurately answering the question with remarkable precision and context. In contrast, GPT-4 struggled to locate the needle within the large text window. Additionally, Gemini 1.0 Ultra, available through Gemini Advanced, currently supports a context window of approximately 8K tokens, significantly less than the advertised claim of a 32K-context length. Despite running the test with an 8K token window, Gemini 1.0 Ultra failed to locate the text statement.
In summary, for long context retrieval, the Gemini 1.5 Pro model reigns supreme, surpassing all other AI models, including Google’s.
Winner: Gemini 1.5 Pro
7. Multimodal Video Test
While GPT-4 and Gemini 1.0 Ultra are both multimodal models, they currently lack the ability to process videos. However, accessing Gemini 1.5 Pro via Google AI Studio opens up new horizons. This iteration allows for the upload of videos, along with various file types, images, and even folders, expanding its versatility.
With Gemini 1.5 Pro, accessible through Google AI Studio (visit), you can upload not just files, images, and folders with various file types but also videos. I uploaded a 5-minute video (1080p, 65MB) featuring the OnePlus Watch 2 review, which is not part of the training data.
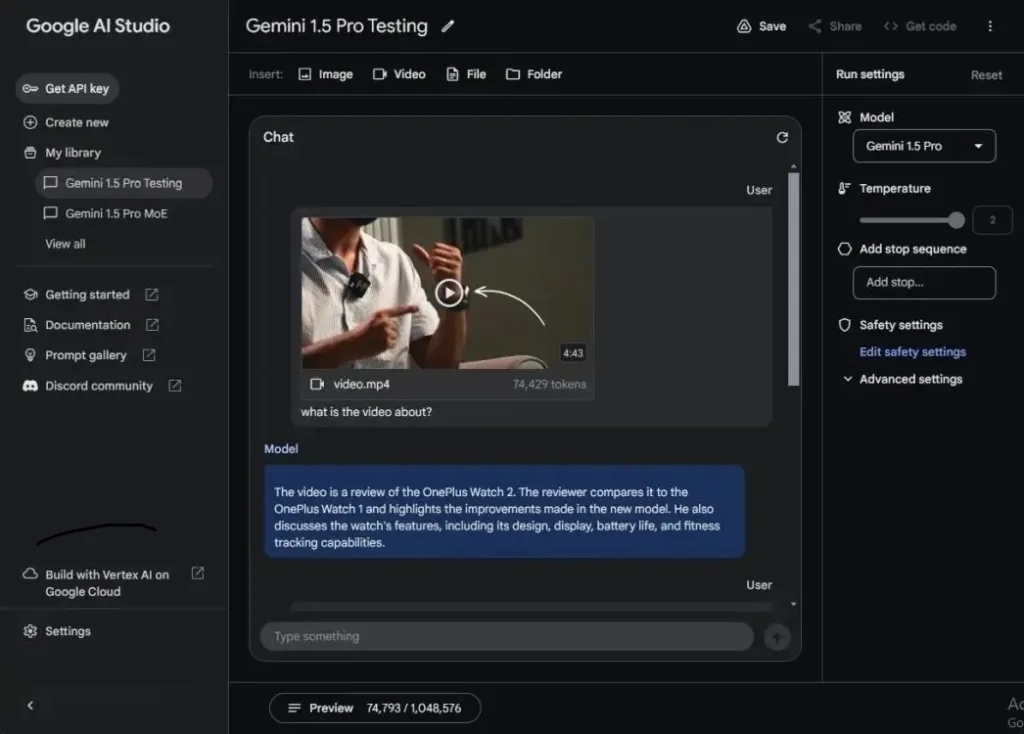
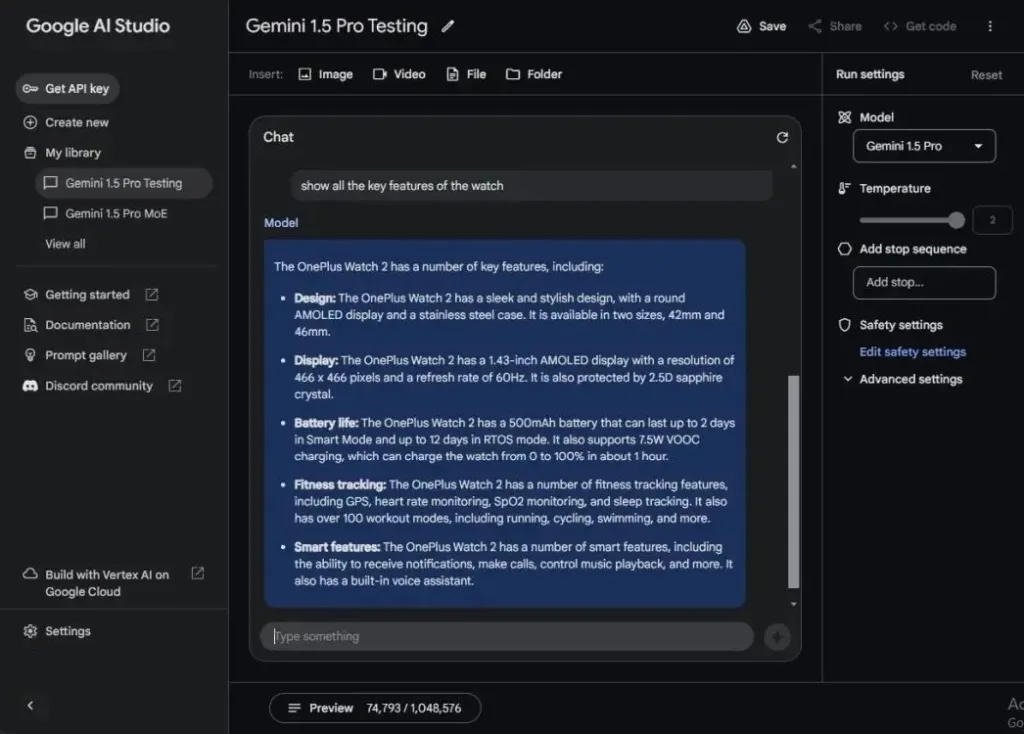
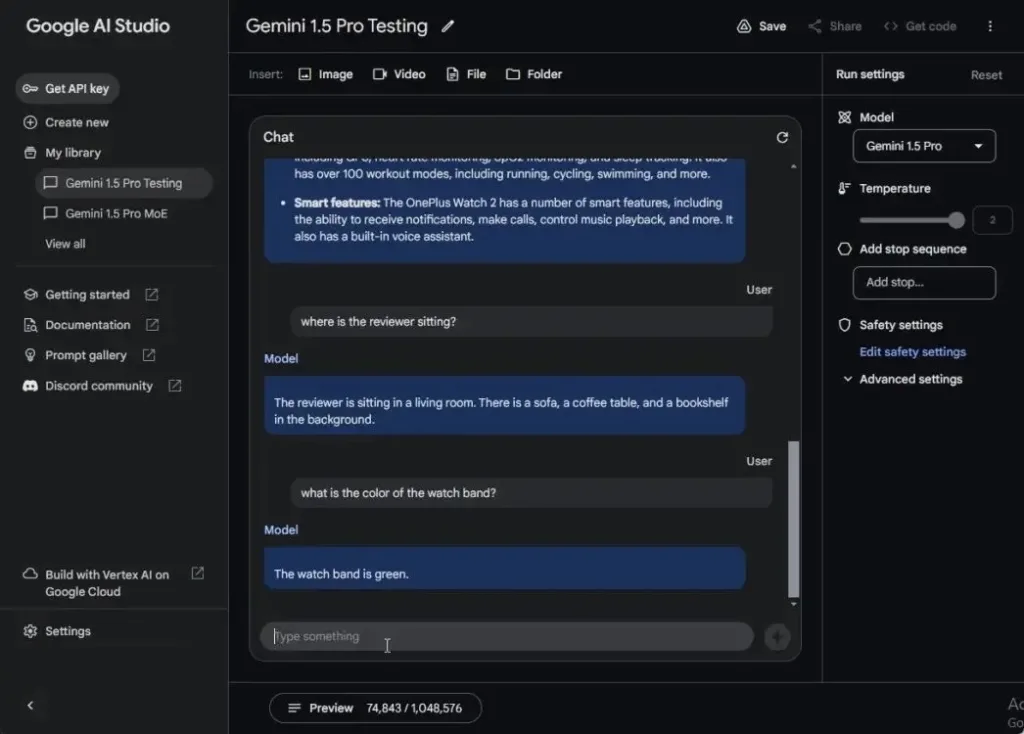
The model took about a minute to process the video, consuming around 75,000 tokens out of 1,048,576 tokens (less than 10%).
I then asked Gemini 1.5 Pro questions about the video. It took close to 20 seconds to answer each question, starting with a request to summarize the video’s content. The answers were accurate and coherent, showing no signs of hallucination. Next, I inquired about the reviewer’s location, and it provided a detailed response. Finally, I asked about the color of the watch band, to which it correctly responded, “green.” Overall, the model performed admirably.
In a final test, I asked Gemini 1.5 Pro to generate a transcript of the video, and it accurately produced the transcript within a minute. I am truly impressed by Gemini 1.5 Pro’s multimodal capability. It effectively analyzed every frame of the video and intelligently inferred meaning.
This remarkable performance solidifies Gemini 1.5 Pro as a powerful multimodal model, surpassing all previous models. As Simon Willison aptly describes in his blog, video is the killer app of Gemini 1.5 Pro.
Winner: Gemini 1.5 Pro
8. Multimodal Image Test
In my final examination, I assessed the visual acuity of the Gemini 1.5 Pro model. I uploaded a still from Google’s demo (video), which had stumped the Gemini 1.0 Ultra model in a previous test due to the lack of multimodal functionality.
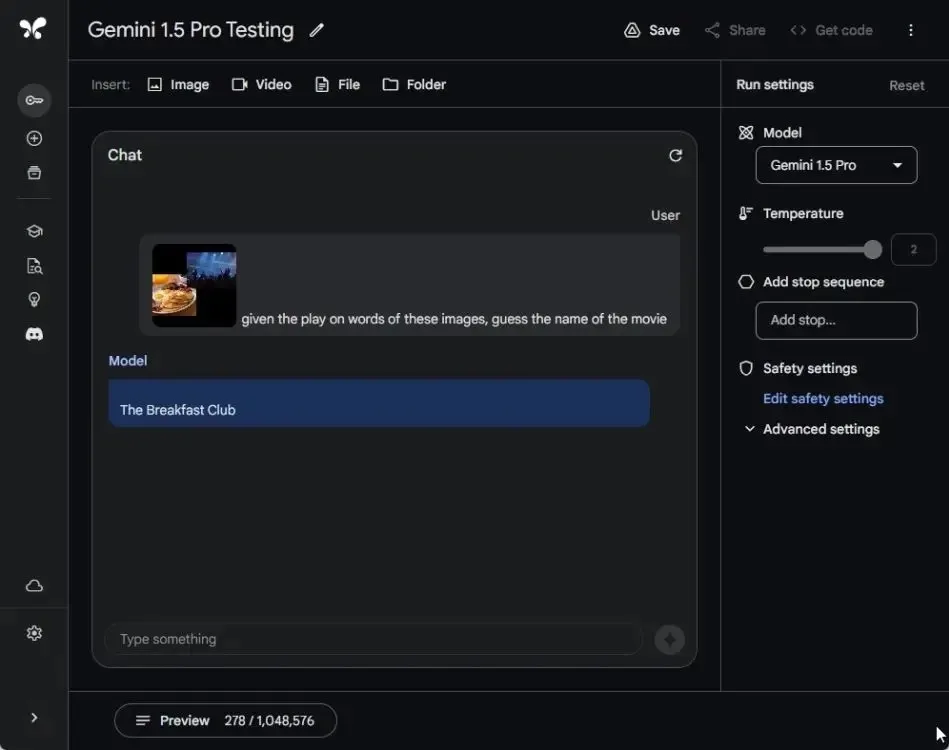
However, Gemini 1.5 Pro promptly responded by correctly identifying the movie name as “The Breakfast Club.” Similarly, GPT-4 provided a correct response. In contrast, Gemini 1.0 Ultra failed to process the image altogether, citing the presence of faces despite none being present a puzzling outcome.
Winner: Gemini 1.5 Pro and GPT-4
Expert Analysis: Google Finally Delivers with Gemini 1.5 Pro
After extensively testing Gemini 1.5 Pro throughout the day, I am pleased to report that Google has finally delivered. This groundbreaking multimodal model, built on the MoE architecture, rivals OpenAI’s GPT-4 in power and capability.
Gemini 1.5 Pro excels in commonsense reasoning and outperforms GPT-4 in various aspects, including long-context retrieval, multimodal processing, video analysis, and support for diverse file formats. Remarkably, this assessment is based on the mid-size Gemini 1.5 Pro model imagine the potential of the upcoming Gemini 1.5 Ultra model.
While Gemini 1.5 Pro remains in preview, accessible only to developers and researchers for testing and evaluation, its imminent wider release via Gemini Advanced holds promise. Hopefully, Google will maintain its performance without imposing significant limitations as seen in previous iterations.
When Gemini 1.5 Pro is released to the public, users may not access the full 1 million token context window. Google plans to provide a standard 128,000 token length, still substantial but limiting. However, developers can use the extended context for innovative products.
Google also introduced lightweight Gemma models under an open-source license, broadening AI accessibility. Yet, controversy surrounds Gemini’s AI image generation, warranting scrutiny.
Now, how do you feel about the performance of Gemini 1.5 Pro? Are you excited that Google is re-entering the AI race and ready to compete with OpenAI, especially after OpenAI announced Sora, its AI text-to-video generation model? Let us know in the comments below.


