
Although large language models (LLMs) excel at complex tasks, smaller models are valuable for local use on smartphones and PCs. Microsoft’s latest development in this area is the Phi-3 Mini model, boasting 3.8 billion parameters in its training.
Two other models within the Phi-3 family exist: Phi-3 Small (7B) and Phi-3 Medium (14B), but they remain unreleased. However, the Phi-3 Mini model, despite its diminutive size, outperforms Meta’s Llama 3 8B model, Google’s Gemma 7B model, and Mistral 7B model in the MMLU benchmark. Remarkably, it matches the performance of Mixtral 8x7b, despite being significantly smaller.
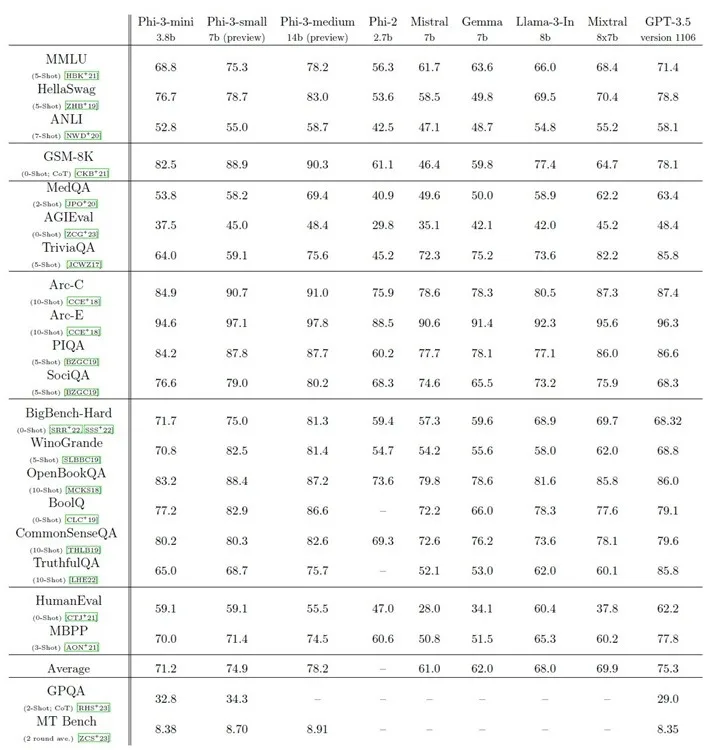
In HumanEval, the Phi-3 Mini model surpasses Gemma 7B and Mistral 7B by a significant margin. Microsoft’s dedication to crafting potent small models for local use on smartphones and PCs is evident. Additionally, the upcoming Phi-3 Small and Phi-3 Medium models outperform OpenAI’s GPT-3.5 model, Mixtral 8x7b, and Llama 3 8B, showcasing Microsoft’s impressive advancements in the field.
Microsoft attributes Phi-3’s exceptional performance to its clean dataset, comprising heavily filtered web data and synthetic data. Moreover, the model undergoes rigorous checks for safety, harm, and robustness. It appears that Phi-3 is poised to reign supreme among smaller models. I’m eager to see how it fares against Anthropic’s Haiku model, the smallest model in the Claude 3 family. Share your excitement in the comments below! In the meantime, you can explore how to run Google’s Gemma model on your PC locally.



