After a long wait, Meta has finally released Llama 3.1 405B, its largest AI model to date, trained on 405 billion parameters. Additionally, Meta has introduced an upgraded family of models, including Llama 3.1 70B and Llama 3.1 8B. All these models are open-source, with Meta emphasizing its “commitment to openly accessible AI.“
Each of the Llama 3.1 models features a context length of 128K tokens and supports eight different languages, incorporating a large context window and multilingual capability. In terms of benchmarks, the largest model, Llama 3.1 405B, outperforms leading AI models from OpenAI, such as GPT-4 and the latest GPT-4o (Omni).
In the MMLU benchmark, Llama 3.1 405B scores 88.6 points, while GPT-4o scores 88.7 points, placing them at nearly the same level. Additionally, in almost all other tests, including MBPP, GSM8K, and the ARC Challenge, the 405B model surpasses GPT-4o. The only major benchmark where Llama 3.1 405B falls slightly behind is HumanEval, but the difference is minimal.
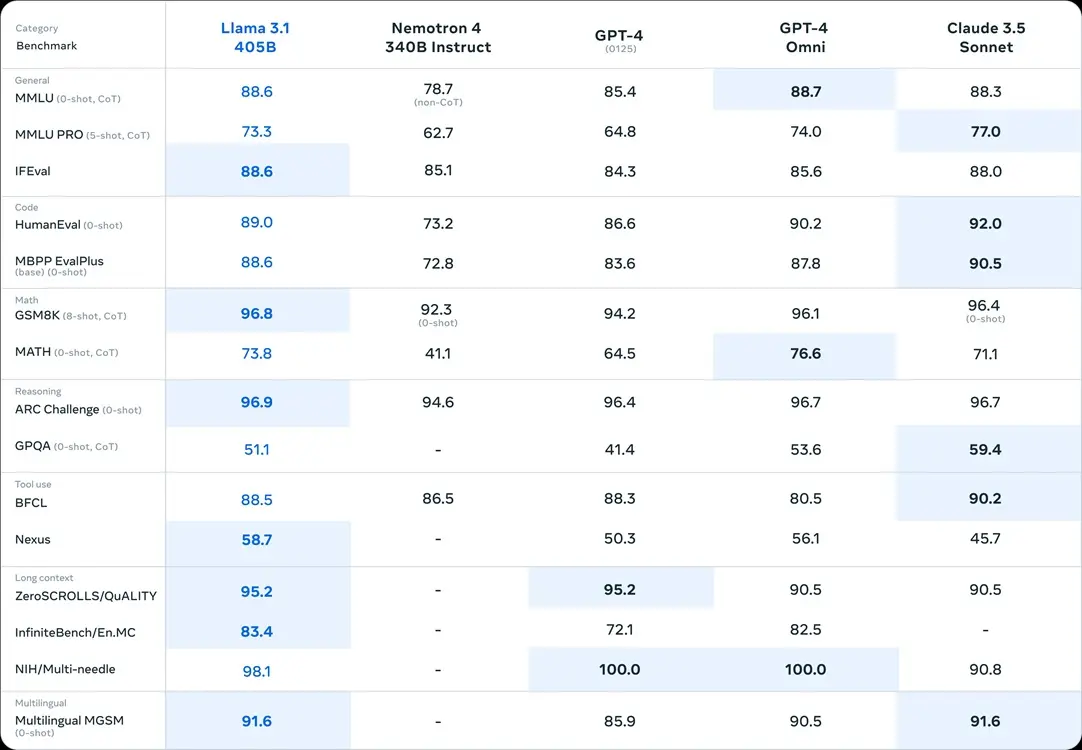
In HumanEval, GPT-4o scores 90.2 points, while the 405B model scores 89.0 points. Unfortunately, Meta has not yet released a truly multimodal model, even with the launch of Llama 3.1. Although Meta claims that Llama 3.1 models support image, video, and speech recognition, these features are still under active development and not yet ready for release.
To experience the performance of the Llama 3.1 405B model, visit groq.com and chat with the frontier model. Be aware that high traffic is causing some server issues at the moment. Additionally, if you’re in the US, you can access the 405B model on WhatsApp and meta.ai (visit).



