

Since OpenAI’s release of ChatGPT in 2022, technological advancements have surged, with no signs of slowing down. Companies like Google, Microsoft, Meta, Anthropic, and many others have introduced AI chatbots, all powered by Large Language Models (LLMs). But what exactly are LLMs, and how do they function? Read our explainer below to find out.
A Simple Definition of LLM
A Large Language Model (LLM) is a form of Artificial Intelligence (AI) that is trained on vast text datasets. Designed to understand and generate human language based on probability, it functions as a deep-learning algorithm. LLMs can generate essays, poems, articles, letters, and code, as well as translate and summarize texts, among other capabilities.
The size of a training dataset significantly influences the natural language processing (NLP) abilities of an LLM. Generally, AI researchers classify LLMs with 2 billion or more parameters as “large.” Parameters refer to the variables on which the model is trained; a larger parameter count indicates a more capable model.
For instance, when OpenAI introduced the GPT-2 LLM in 2019, it was trained on 1.5 billion parameters. In 2020, GPT-3 followed with 175 billion parameters, marking a significant increase—over 116 times larger. The latest GPT-4 model, considered state-of-the-art, boasts 1.76 trillion parameters.
As time progresses, the parameter size is increasing, enhancing the advanced and more complex capabilities of large language models.
How LLMs Work: The Training Process
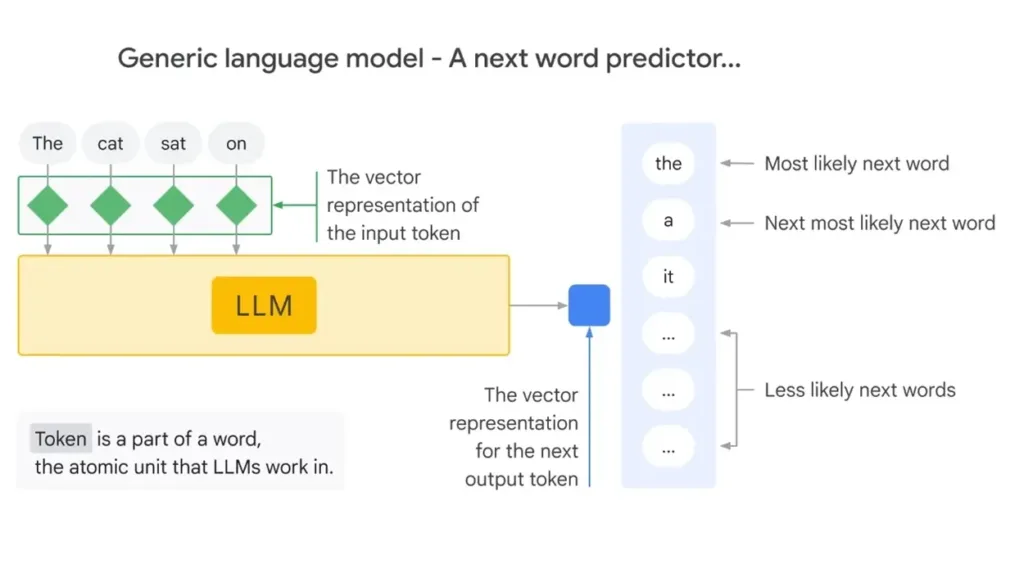
Simply put, LLMs learn to predict the next word in a sentence. This learning process, known as pre-training, involves training the model on a large corpus of text from various sources like books, articles, news, websites, Wikipedia, and more.
During pre-training, the model learns language fundamentals such as grammar, syntax, world knowledge, reasoning abilities, and patterns. After pre-training, the model undergoes fine-tuning. Fine-tuning entails training the LLM on specialized datasets designed for specific tasks.
For instance, to enhance an LLM’s coding capabilities, it would be fine-tuned on extensive coding datasets. Similarly, for tasks like creative writing, the model would be trained on a diverse range of literature, poems, and other relevant materials.
What is the Transformer Architecture for LLMs?
Almost all modern LLMs are based on the transformer architecture. Before transformers, neural network architectures such as RNN (Recurrent Neural Network), CNN (Convolutional Neural Network), and others were prevalent in the field of natural language processing.
In 2017, researchers from the Google Brain team published a groundbreaking paper titled “Attention is All You Need” (Vaswani, et al). This paper introduced the Transformer architecture, which has since become fundamental to LLMs for natural language tasks. Central to the transformer architecture is the concept of self-attention.

It can process all words in a sentence in parallel, understanding their context and relationships. This parallelism also enhances training efficiency. After the paper’s release, Google introduced the first transformer-based LLM named BERT in 2018. Subsequently, OpenAI also adopted this architecture and released its first model, GPT-1.
Applications of LLMs
LLMs now drive AI chatbots like ChatGPT, Gemini, Microsoft Copilot, and others, performing various NLP tasks such as text generation, translation, summarization, code generation, and creative writing like stories and poems. They are also utilized as conversational assistants.
OpenAI recently showcased its GPT-4o model, notable for its engaging conversational abilities. Furthermore, LLMs are currently being tested for developing AI agents capable of performing tasks on behalf of users. Both OpenAI and Google are actively working to advance AI agent technology for future applications.
Overall, LLMs are extensively deployed as customer chatbots and for content generation. Despite their increasing prevalence, machine learning researchers argue that achieving AGI artificial general intelligence surpassing human capabilities will require another breakthrough.
While significant breakthroughs in the Generative AI era have not yet emerged, some researchers speculate that training significantly larger LLMs could potentially lead to AI models exhibiting some form of consciousness.


