To operate a local LLM, you have LM Studio, which lacks support for ingesting local documents. While there’s GPT4ALL, I find it overly complex. PrivateGPT, on the other hand, offers a command-line interface that might not be suitable for average users. Enter AnythingLLM, featuring a sleek graphical user interface that enables you to locally feed documents and interact with your files, even on consumer-grade computers. I extensively used AnythingLLM and found it superior to other solutions. Here’s how you can use it:
Download and Set Up AnythingLLM
1. Download AnythingLLM from here. Available for all cross-platforms such as Windows, macOS, and Linux.
2. Run the setup file to install AnythingLLM, which may take some time.
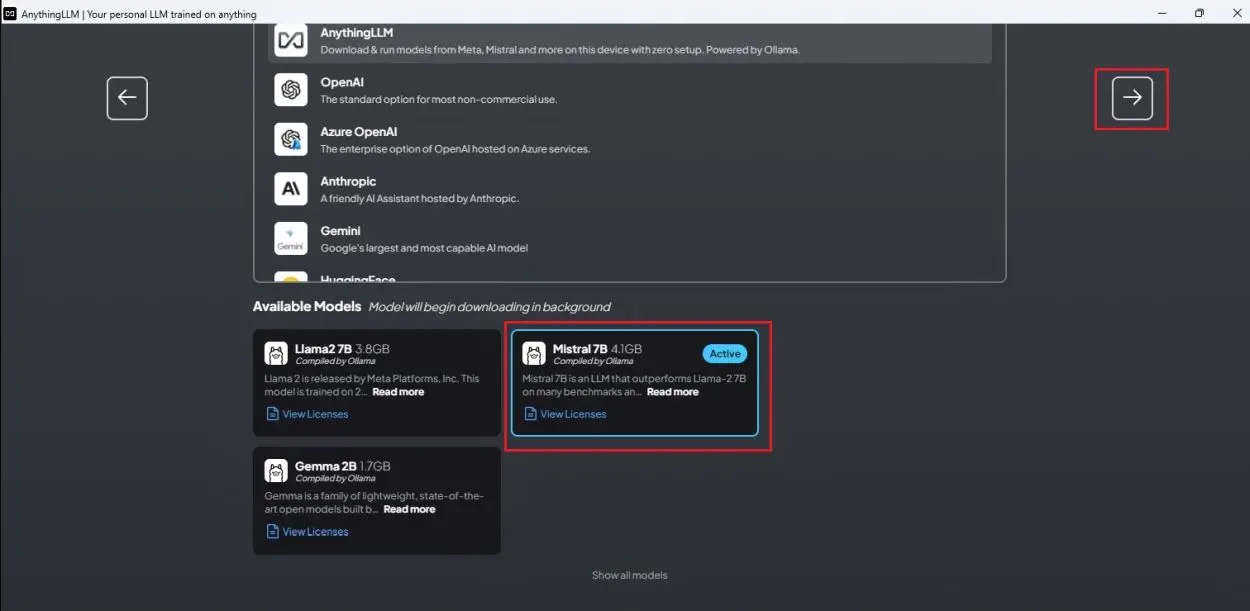
3. Click on “Get started” and scroll down to select an LLM. I chose “Mistral 7B,” but you can download smaller models from the list below.
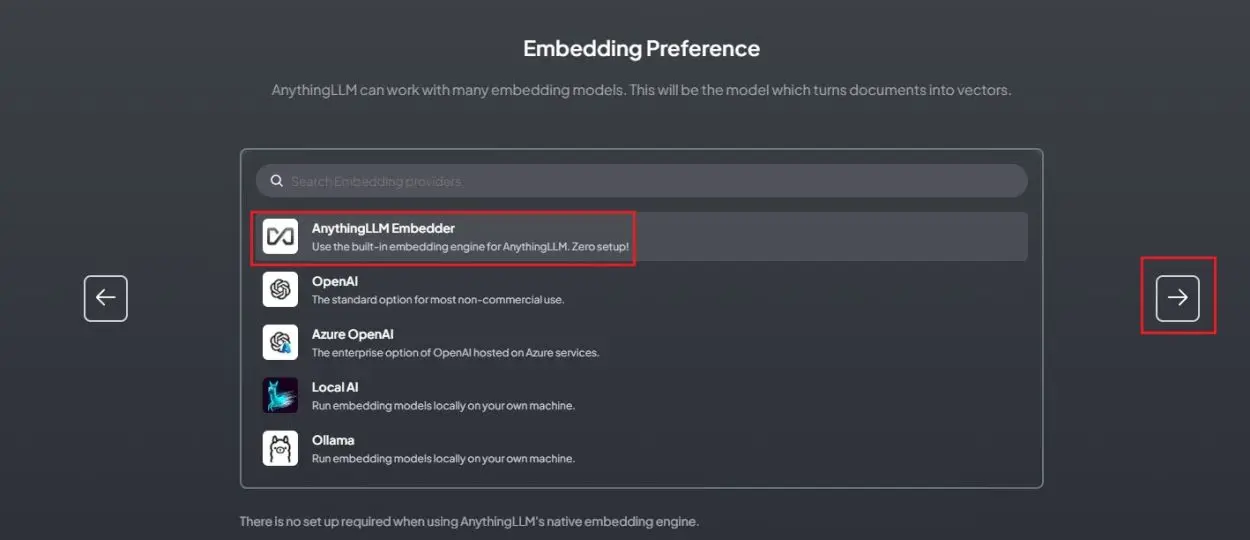
4. Start by selecting “AnythingLLM Embedder,” which requires no manual setup.
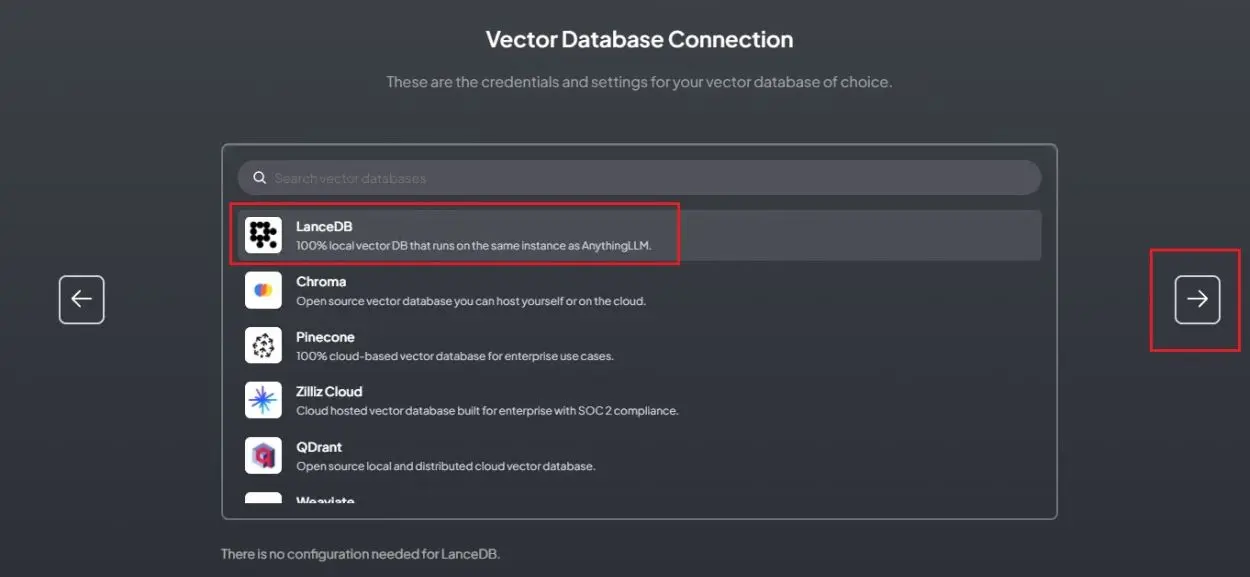
5. Then, choose “LanceDB,” a local vector database.
6. Review your selections and complete the information on the next page. You can skip the survey as well.

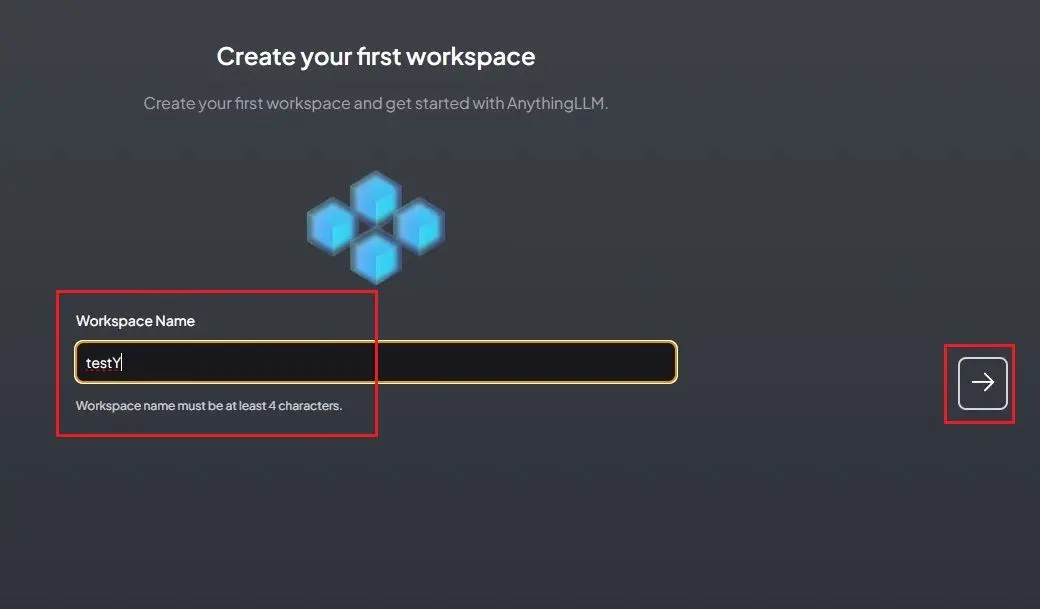
7. Name your workspace.
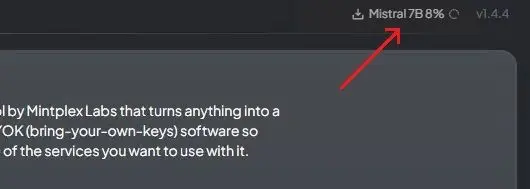
8. Almost there! Notice that Mistral 7B is downloading in the background. Proceed to the next step once the LLM is downloaded.
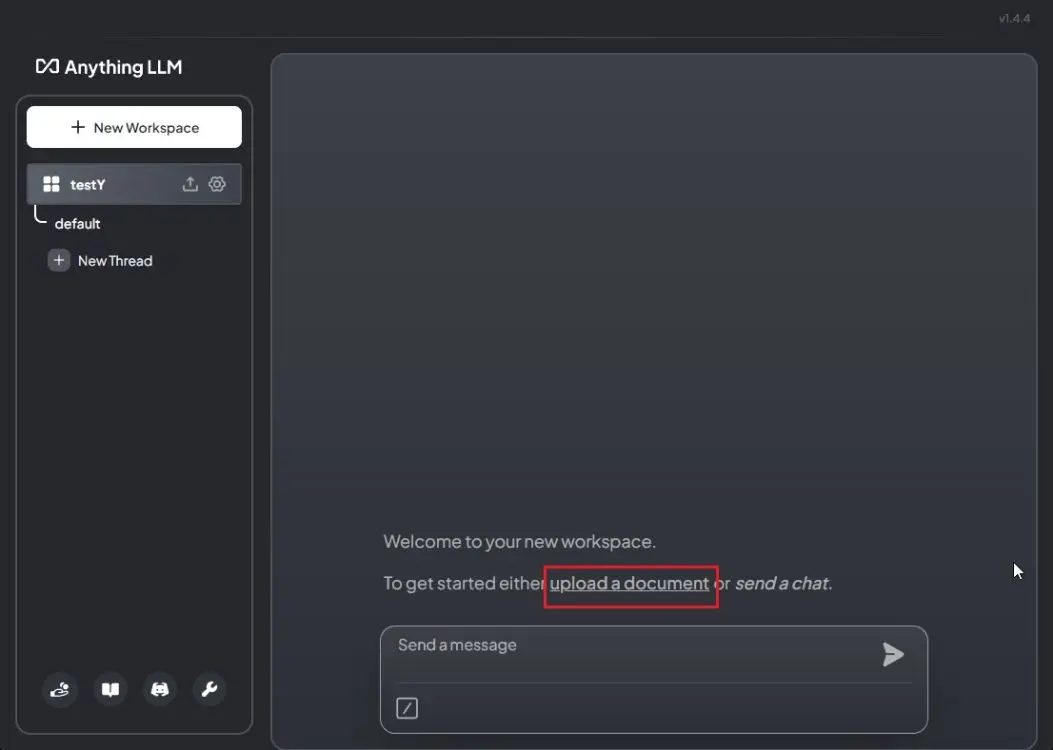
Upload Your Documents and Chat Locally
1. Click on “Upload a document.”
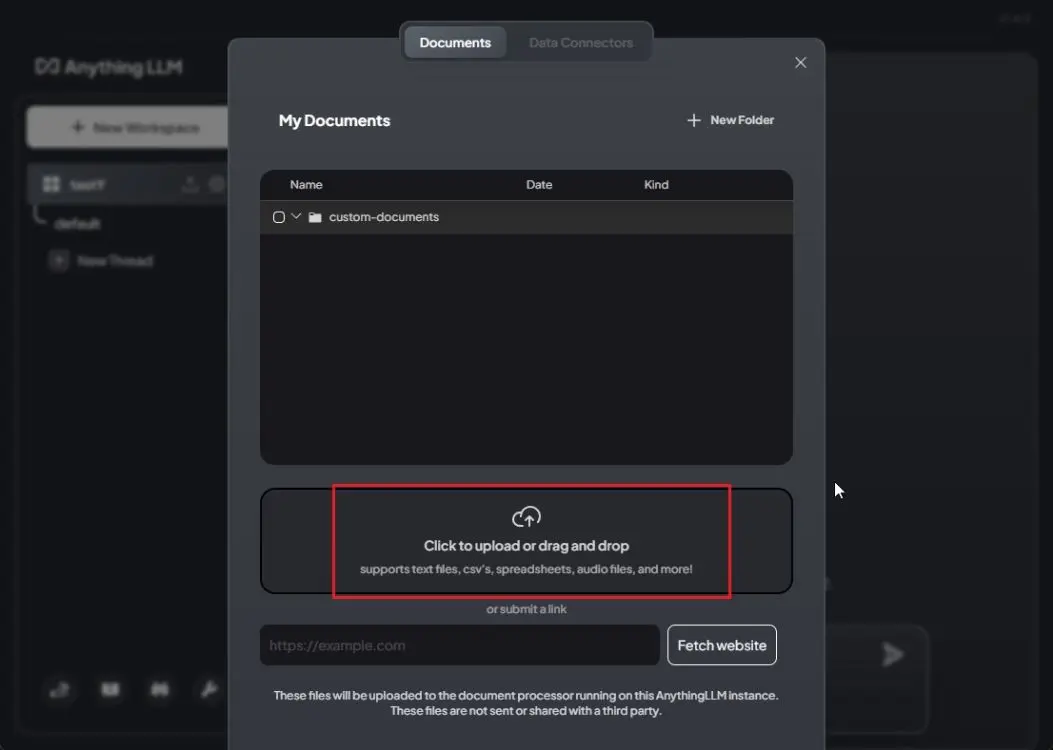
2. Upload your file by clicking or dragging and dropping. Any file format is supported, including PDF, TXT, CSV, and audio files.
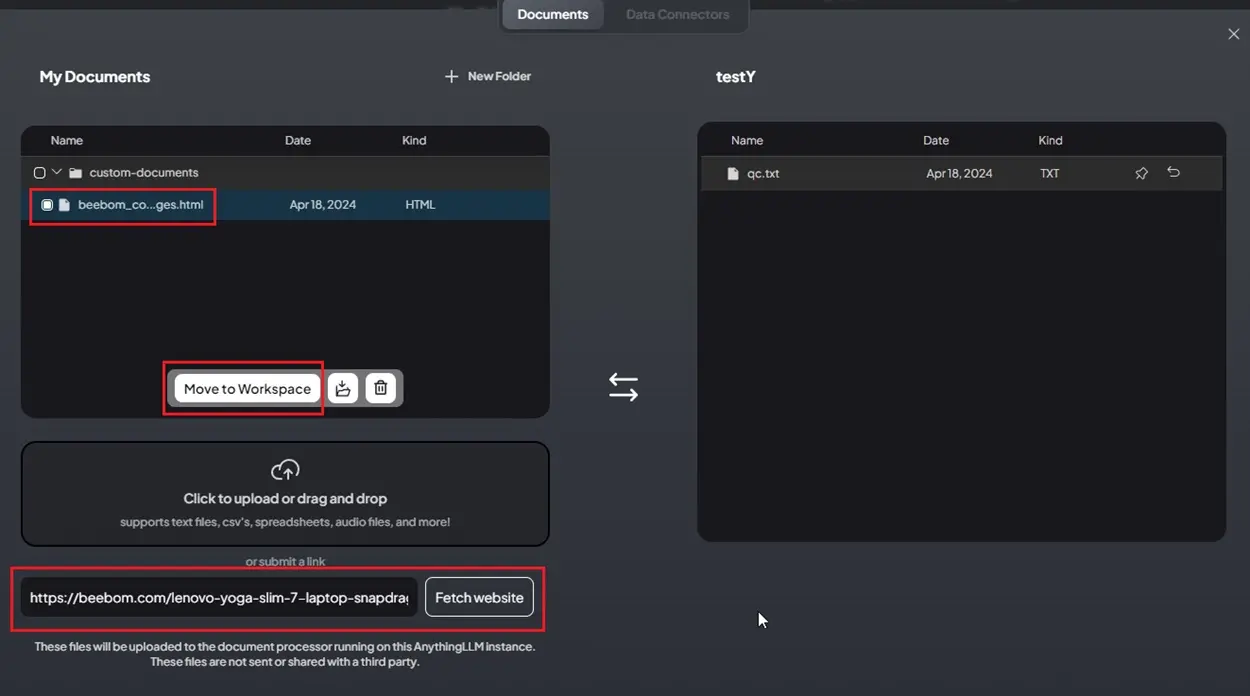
3. After uploading a TXT file, select it and click on “Move to Workspace.”
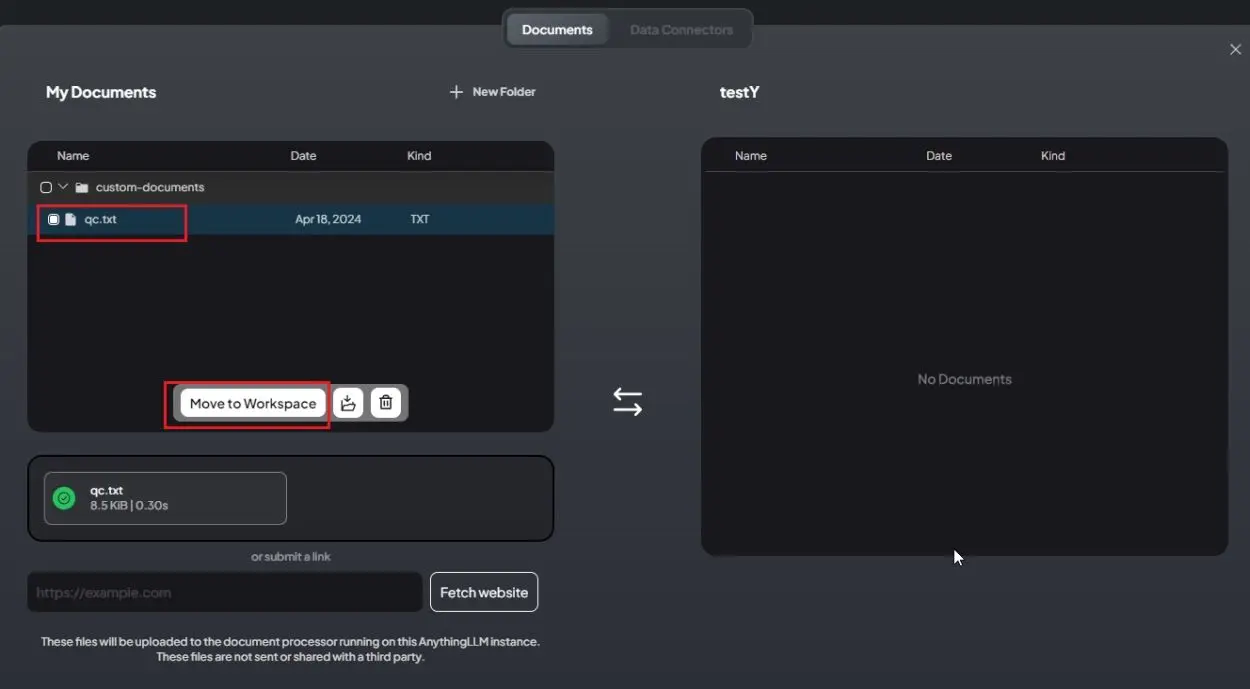
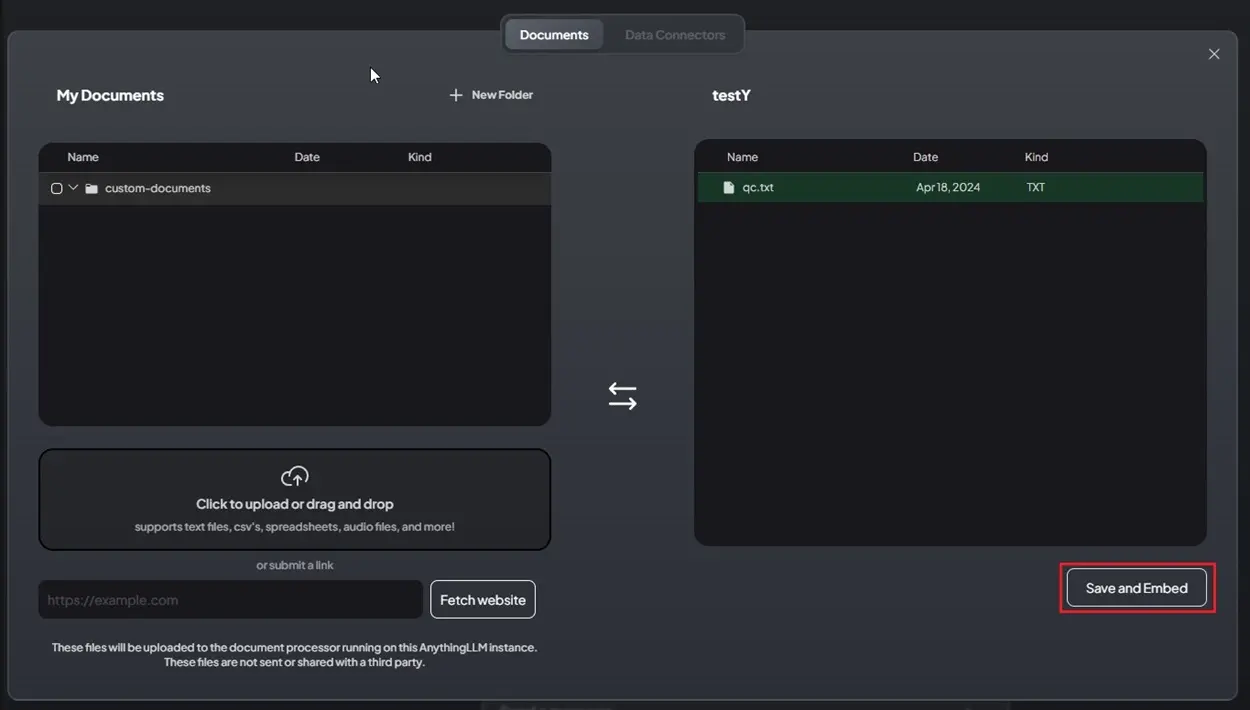
4. Click on the button “Save and Embed,” further close the window.
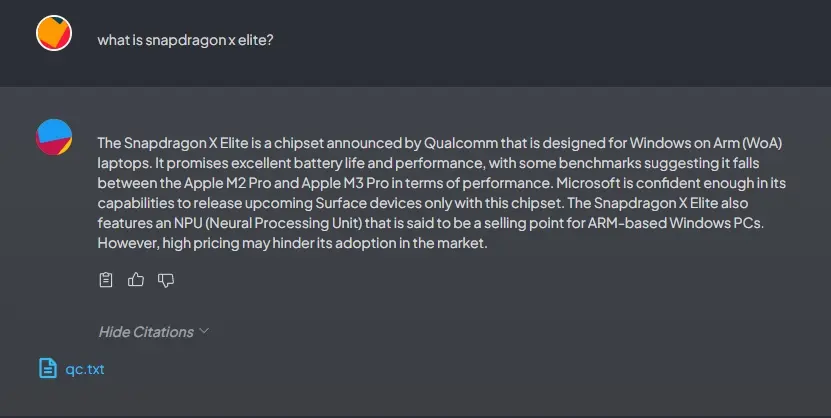
5. You can now start chatting with your documents locally. For example, asking a question from the TXT file yields a correct reply citing the text file.
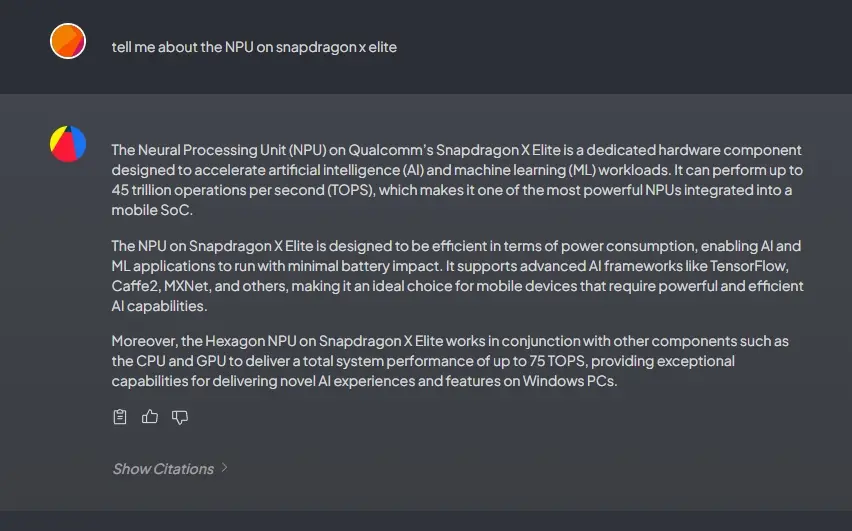
6. Continue asking questions, and you’ll receive accurate responses.
7. Additionally, you can input a website URL, and it will fetch the content from the website. Now, you can start chatting with the LLM.
This method allows you to ingest your documents and files locally and securely chat with the LLM. There’s no need to upload your private documents to cloud servers with uncertain privacy policies. Nvidia has also introduced a similar program called Chat with RTX, but it only functions with high-end Nvidia GPUs. AnythingLLM provides local inferencing even on consumer-grade computers, utilizing both CPU and GPU on any silicon.


